我正在尝试使用LSTM自编码器(Keras)重构时间序列数据。 现在,我想在少量样本(5个样本,每个样本长500个时间步长,有1个维度)上训练自编码器。我希望确保模型能够重构这5个样本,之后再使用所有数据(6000个样本)。
window_size = 500
features = 1
data = data.reshape(5, window_size, features)
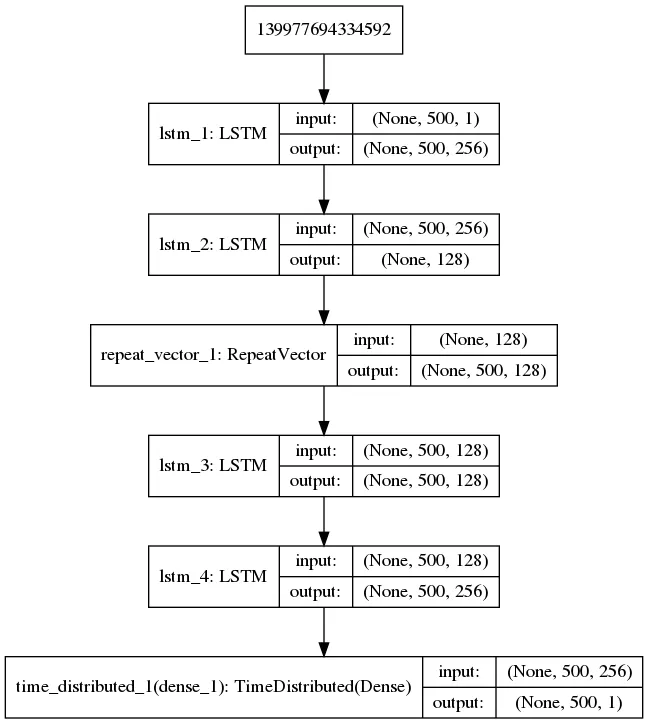
model = Sequential()
model.add(LSTM(256, input_shape=(window_size, features),
return_sequences=True))
model.add(LSTM(128, input_shape=(window_size, features),
return_sequences=False))
model.add(RepeatVector(window_size))
model.add(LSTM(128, input_shape=(window_size, features),
return_sequences=True))
model.add(LSTM(256, input_shape=(window_size, features),
return_sequences=True))
model.add(TimeDistributed(Dense(1)))
model.compile(optimizer='adam', loss='mse')
model.fit(data, data, epochs=100, verbose=1)
{kind=link}
训练:
Epoch 1/100
5/5 [==============================] - 2s 384ms/step - loss: 0.1603
...
Epoch 100/100
5/5 [==============================] - 2s 388ms/step - loss: 0.0018
训练后,我尝试重新构建其中的5个样本之一:
yhat = model.predict(np.expand_dims(data[1,:,:], axis=0), verbose=0)
重构:蓝色
输入:橙色
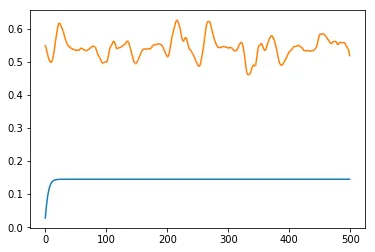
当损失很小时,为什么重构效果如此糟糕?我该如何改进模型呢?谢谢。
{kind=link}
data[0,:,:]到data[4,:,:]的所有图表吗? - Daniel Möller