我正在使用Keras,在预训练的ResNet50网络上应用迁移学习。我有带二进制类标签的图像补丁,并希望使用CNN来预测未见过的图像补丁中[0;1]范围内的类标签。
- 网络:使用ImageNet预训练的ResNet50 ,加入了3层
- 数据:70305个训练样本,8000个验证样本,66823个测试样本,所有样本都有平衡数量的类标签
- 图像:3个波段(RGB)和224x224个像素
设置:32批次,卷积层大小:16
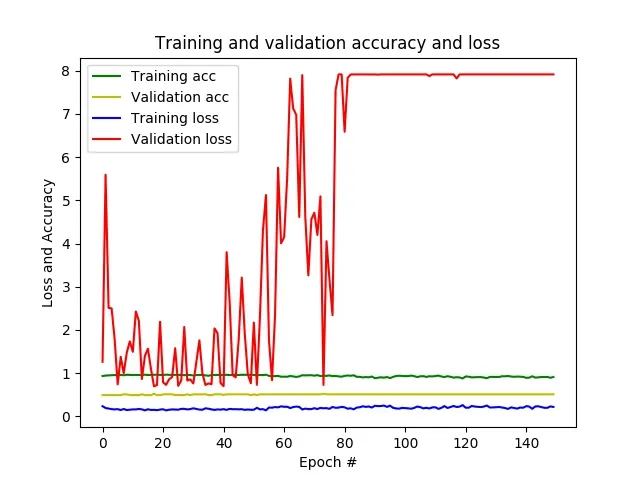
结果:几个epoch后,准确率已经接近1,损失接近0,而在验证数据上,准确率保持在0.5左右,损失每个epoch会有所变化。最终,CNN对所有未见过的补丁只预测一个类别。
- 问题:似乎我的网络出现了过拟合。
以下策略可以减少过拟合:
- 增加批次大小
- 减小完全连接层的大小
- 添加dropout层
- 添加数据增强
- 通过修改损失函数应用正则化方法
- 解冻更多的预训练层
- 使用不同的网络架构
我已经尝试了最大512个批次大小,并改变了完全连接层的大小,但并没有取得太大成功。在随机测试其余策略之前,我想询问如何调查出现问题的原因,以找出上述策略中哪一个具有最大潜力。
以下是我的代码:
def generate_data(imagePathTraining, imagesize, nBatches):
datagen = ImageDataGenerator(rescale=1./255)
generator = datagen.flow_from_directory\
(directory=imagePathTraining, # path to the target directory
target_size=(imagesize,imagesize), # dimensions to which all images found will be resize
color_mode='rgb', # whether the images will be converted to have 1, 3, or 4 channels
classes=None, # optional list of class subdirectories
class_mode='categorical', # type of label arrays that are returned
batch_size=nBatches, # size of the batches of data
shuffle=True) # whether to shuffle the data
return generator
def create_model(imagesize, nBands, nClasses):
print("%s: Creating the model..." % datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
# Create pre-trained base model
basemodel = ResNet50(include_top=False, # exclude final pooling and fully connected layer in the original model
weights='imagenet', # pre-training on ImageNet
input_tensor=None, # optional tensor to use as image input for the model
input_shape=(imagesize, # shape tuple
imagesize,
nBands),
pooling=None, # output of the model will be the 4D tensor output of the last convolutional layer
classes=nClasses) # number of classes to classify images into
print("%s: Base model created with %i layers and %i parameters." %
(datetime.now().strftime('%Y-%m-%d_%H-%M-%S'),
len(basemodel.layers),
basemodel.count_params()))
# Create new untrained layers
x = basemodel.output
x = GlobalAveragePooling2D()(x) # global spatial average pooling layer
x = Dense(16, activation='relu')(x) # fully-connected layer
y = Dense(nClasses, activation='softmax')(x) # logistic layer making sure that probabilities sum up to 1
# Create model combining pre-trained base model and new untrained layers
model = Model(inputs=basemodel.input,
outputs=y)
print("%s: New model created with %i layers and %i parameters." %
(datetime.now().strftime('%Y-%m-%d_%H-%M-%S'),
len(model.layers),
model.count_params()))
# Freeze weights on pre-trained layers
for layer in basemodel.layers:
layer.trainable = False
# Define learning optimizer
optimizerSGD = optimizers.SGD(lr=0.01, # learning rate.
momentum=0.0, # parameter that accelerates SGD in the relevant direction and dampens oscillations
decay=0.0, # learning rate decay over each update
nesterov=False) # whether to apply Nesterov momentum
# Compile model
model.compile(optimizer=optimizerSGD, # stochastic gradient descent optimizer
loss='categorical_crossentropy', # objective function
metrics=['accuracy'], # metrics to be evaluated by the model during training and testing
loss_weights=None, # scalar coefficients to weight the loss contributions of different model outputs
sample_weight_mode=None, # sample-wise weights
weighted_metrics=None, # metrics to be evaluated and weighted by sample_weight or class_weight during training and testing
target_tensors=None) # tensor model's target, which will be fed with the target data during training
print("%s: Model compiled." % datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
return model
def train_model(model, nBatches, nEpochs, imagePathTraining, imagesize, nSamples, valX,valY, resultPath):
history = model.fit_generator(generator=generate_data(imagePathTraining, imagesize, nBatches),
steps_per_epoch=nSamples//nBatches, # total number of steps (batches of samples)
epochs=nEpochs, # number of epochs to train the model
verbose=2, # verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch
callbacks=None, # keras.callbacks.Callback instances to apply during training
validation_data=(valX,valY), # generator or tuple on which to evaluate the loss and any model metrics at the end of each epoch
class_weight=None, # optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function
max_queue_size=10, # maximum size for the generator queue
workers=32, # maximum number of processes to spin up when using process-based threading
use_multiprocessing=True, # whether to use process-based threading
shuffle=True, # whether to shuffle the order of the batches at the beginning of each epoch
initial_epoch=0) # epoch at which to start training
print("%s: Model trained." % datetime.now().strftime('%Y-%m-%d_%H-%M-%S'))
return history
lr=0.01减少到接近零的值吗?您所说的不同度量是什么意思?“decay=0.0”是keras文档中的默认值。我想我需要更多了解损失函数参数的工作原理。 - Sophie Crommelinck