我有一个包含约9K行和57列的数据框,称为“df”。
我需要创建一个新的数据框:“df_final”,对于“df”的每一行,我需要复制每一行“x”次,并依次递增每一行中的日期,“x”次。尽管我可以完成几次迭代,但当我对“df”的全长(即len(df))进行操作时,这个循环时间太长了(>3小时),我不得不取消它。我从未看到过它的结束。以下是当前的代码:
' df'的前两行循环的结果如下:
第一、二行df: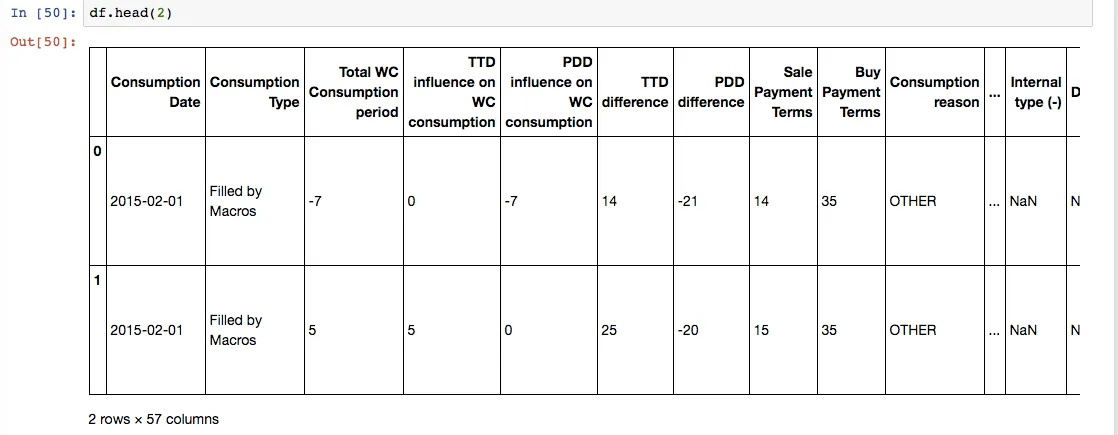 期望的结果:
期望的结果:
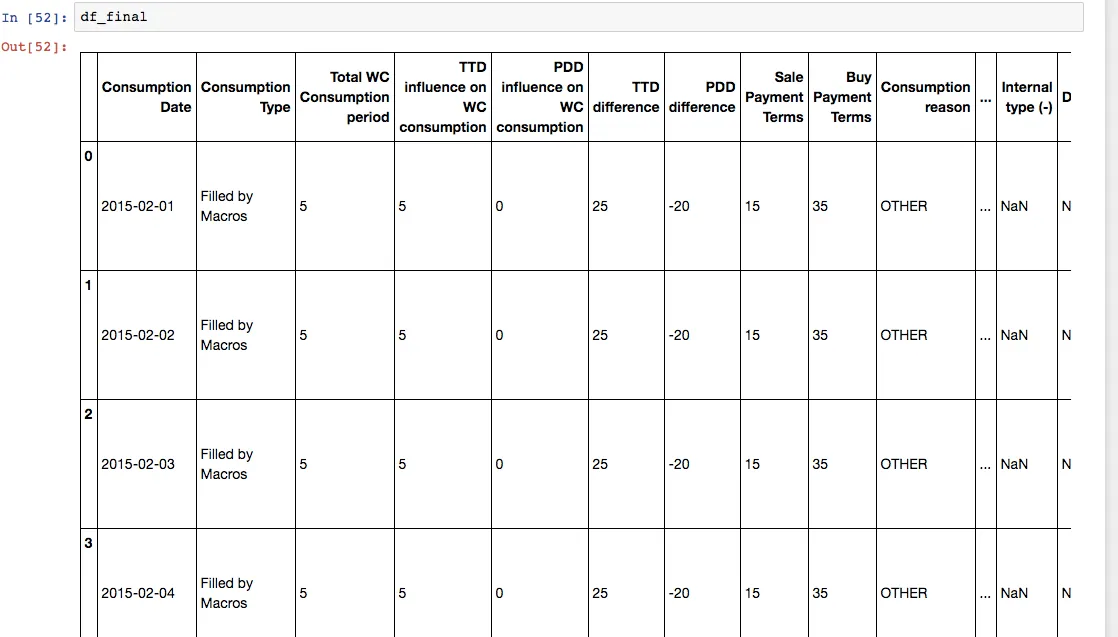 是否有其他方法来获得所需的输出。似乎pandas不太擅长处理循环。在VBA excel中,同样的循环需要大约3/4分钟...我正在尝试将当前在excel中的过程更改为python,但是,如果无法使其正常工作,我想我会坚持旧方法...
是否有其他方法来获得所需的输出。似乎pandas不太擅长处理循环。在VBA excel中,同样的循环需要大约3/4分钟...我正在尝试将当前在excel中的过程更改为python,但是,如果无法使其正常工作,我想我会坚持旧方法...
我需要创建一个新的数据框:“df_final”,对于“df”的每一行,我需要复制每一行“x”次,并依次递增每一行中的日期,“x”次。尽管我可以完成几次迭代,但当我对“df”的全长(即len(df))进行操作时,这个循环时间太长了(>3小时),我不得不取消它。我从未看到过它的结束。以下是当前的代码:
df.shape
output: (9454, 57)
df_int = df[0:0]
df_final = df_int[0:0]
range_df = len(df)
for x in range(0,2):
df_int = df.iloc[0+x:x+1]
if abs(df_int.iat[-1,3]) > 0:
df_int = pd.concat([df_int]*abs(df_int.iat[-1,3]), ignore_index=True)
for i in range(1, abs(df_int.iat[-1,3])):
df_int['Consumption Date'][i] = df_int['Consumption Date'][i-1] + datetime.timedelta(days = 1)
i += 1
df_final = df_final.append(df_int, ignore_index=True)
x += 1
' df'的前两行循环的结果如下:
第一、二行df:
期望的结果:
是否有其他方法来获得所需的输出。似乎pandas不太擅长处理循环。在VBA excel中,同样的循环需要大约3/4分钟...我正在尝试将当前在excel中的过程更改为python,但是,如果无法使其正常工作,我想我会坚持旧方法...