我有一张表
我在这两列上为该表建立了一个索引,
我想要获取每个
我本以为优化器能够找到每个唯一的
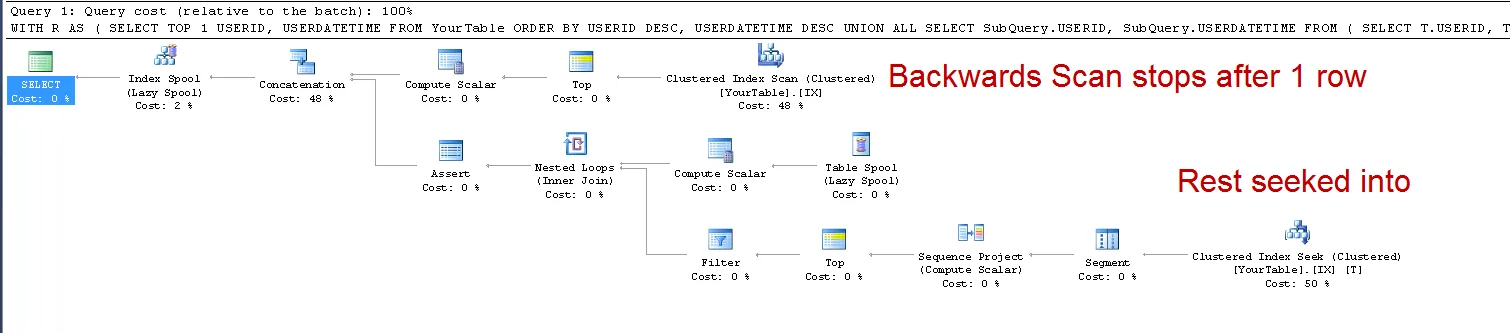
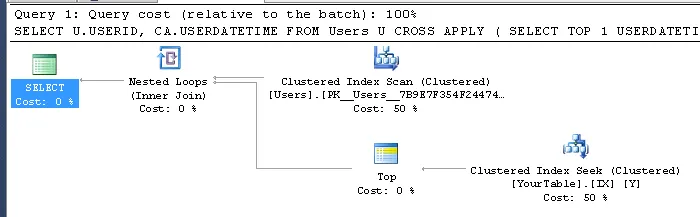
为什么SQL不以减少处理行数的方式使用索引?
MYTABLE,大约有25列,其中两列是USERID (整数)和USERDATETIME (日期时间)。我在这两列上为该表建立了一个索引,
USERID是第一列,后面是USERDATETIME。我想要获取每个
USERID的最大USERDATETIME。因此:select USERID,MAX(USERDATETIME)
from MYTABLE WHERE USERDATETIME < '2015-10-11'
GROUP BY USERID
我本以为优化器能够找到每个唯一的
USERID和最大的USERDATETIME,并且寻找次数等于唯一USERID数量的。我认为这应该很快。我的表中有2000个用户id和600万行数据。然而,实际执行计划显示从索引扫描中获取了600万行。如果我使用一个带有USERDATETIME/USERID的索引,则计划更改为使用索引查找,但仍然处理了600万行。为什么SQL不以减少处理行数的方式使用索引?