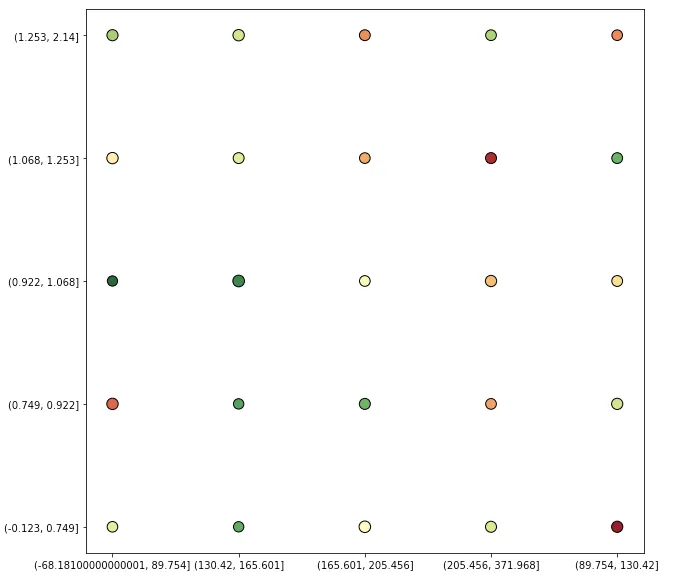
我希望创建一个散点图,将我的数据总结到ntiles中。由于散点图无法将区间类型作为坐标轴参数进行处理,因此我将值转换为字符串,但这样会导致区间的顺序丢失。请注意,下面的x轴未按从低到高排序。如何保留顺序?
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors
import numpy as np
n_tile = 5
np.random.seed(0)
x = np.random.normal(150, 70, 3000,)
y = np.random.normal(1, 0.3, 3000)
r = np.random.normal(0.4, 0.1, 3000)
plot_data = pd.DataFrame({
'x': x,
'y': y,
'r': r
})
plot_data['x_group'] = pd.qcut(plot_data['x'], n_tile, duplicates='drop')
plot_data['y_group'] = pd.qcut(plot_data['y'], n_tile, duplicates='drop')
plot_data_grouped = plot_data.groupby(['x_group','y_group'], as_index=False).agg({'r':['mean','count']})
plot_data_grouped.columns = ['x','y','mean','count']
cmap = plt.cm.rainbow
norm = matplotlib.colors.Normalize(vmin=0, vmax=1)
plt.figure(figsize=(10,10))
plt.scatter(x=[str(x) for x in plot_data_grouped['x']],
y=[str(x) for x in plot_data_grouped['y']],
s=plot_data_grouped["count"],
c=plot_data_grouped['mean'], cmap="RdYlGn", edgecolors="black")
plt.show()
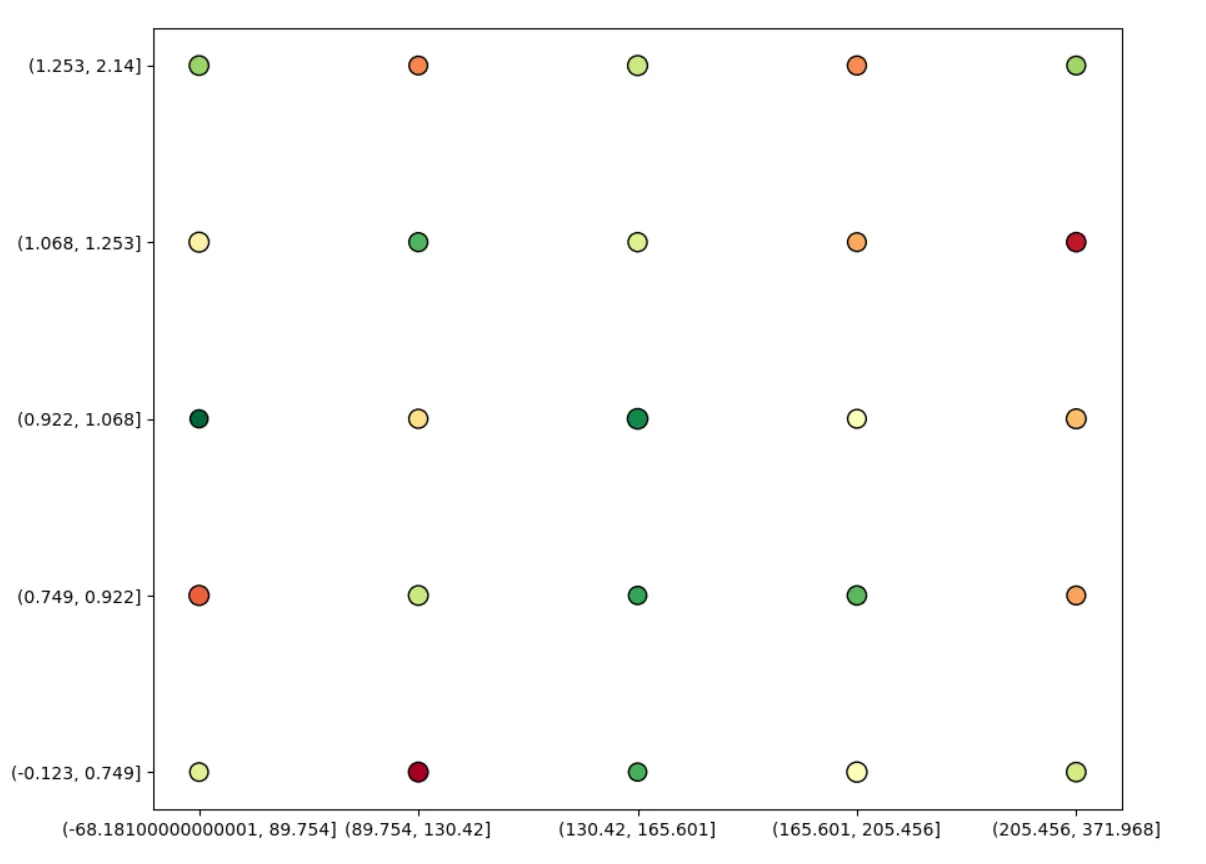
plt.scatter之前对数据进行排序了吗? - William Miller