我正在像这样将数据连接到numpy数组中:
xdata_test = np.concatenate((xdata_test,additional_X))
这是一千次完成的操作。数组的数据类型为float32,它们的大小如下所示:
xdata_test.shape : (x1,40,24,24) (x1 : [500~10500])
additional_X.shape : (x2,40,24,24) (x2 : [0 ~ 500])
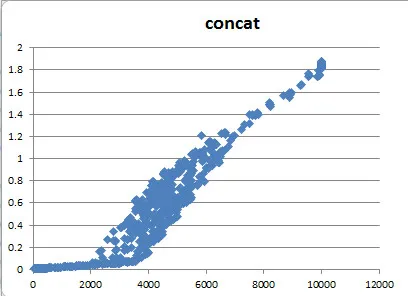
问题在于当
x1大于2000-3000时,连接操作需要更长的时间。下面的图表显示了连接时间与
x2维度大小之间的关系:
 这是内存问题还是numpy的基本特性?
这是内存问题还是numpy的基本特性?
concatenate创建一个正确大小的空结果数组,然后将每个来源的数据复制到其中。 一次性连接操作会产生更少的复制。 - hpaulj