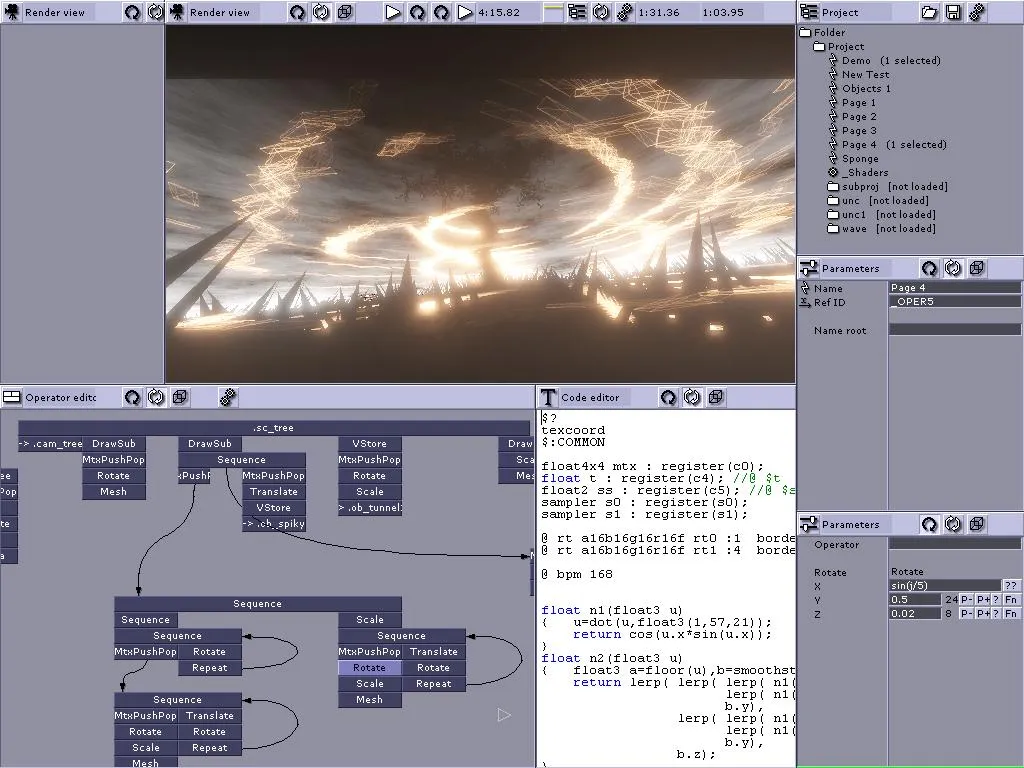
概述
我正在尝试使用某种DFS迭代算法遍历有向循环图。这是我目前实现的一个小型mcve版本(它不处理循环):
class Node(object):
def __init__(self, name):
self.name = name
def start(self):
print '{}_start'.format(self)
def middle(self):
print '{}_middle'.format(self)
def end(self):
print '{}_end'.format(self)
def __str__(self):
return "{0}".format(self.name)
class NodeRepeat(Node):
def __init__(self, name, num_repeats=1):
super(NodeRepeat, self).__init__(name)
self.num_repeats = num_repeats
def dfs(graph, start):
"""Traverse graph from start node using DFS with reversed childs"""
visited = {}
stack = [(start, "")]
while stack:
# To convert dfs -> bfs
# a) rename stack to queue
# b) pop becomes pop(0)
node, parent = stack.pop()
if parent is None:
if visited[node] < 3:
node.end()
visited[node] = 3
elif node not in visited:
if visited.get(parent) == 2:
parent.middle()
elif visited.get(parent) == 1:
visited[parent] = 2
node.start()
visited[node] = 1
stack.append((node, None))
# Maybe you want a different order, if it's so, don't use reversed
childs = reversed(graph.get(node, []))
for child in childs:
if child not in visited:
stack.append((child, node))
if __name__ == "__main__":
Sequence1 = Node('Sequence1')
MtxPushPop1 = Node('MtxPushPop1')
Rotate1 = Node('Rotate1')
Repeat1 = NodeRepeat('Repeat1', num_repeats=2)
Sequence2 = Node('Sequence2')
MtxPushPop2 = Node('MtxPushPop2')
Translate = Node('Translate')
Rotate2 = Node('Rotate2')
Rotate3 = Node('Rotate3')
Scale = Node('Scale')
Repeat2 = NodeRepeat('Repeat2', num_repeats=3)
Mesh = Node('Mesh')
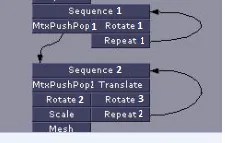
cyclic_graph = {
Sequence1: [MtxPushPop1, Rotate1],
MtxPushPop1: [Sequence2],
Rotate1: [Repeat1],
Sequence2: [MtxPushPop2, Translate],
Repeat1: [Sequence1],
MtxPushPop2: [Rotate2],
Translate: [Rotate3],
Rotate2: [Scale],
Rotate3: [Repeat2],
Scale: [Mesh],
Repeat2: [Sequence2]
}
dfs(cyclic_graph, Sequence1)
print '-'*80
a = Node('a')
b = Node('b')
dfs({
a : [b],
b : [a]
}, a)
上面的代码正在测试一些情况,第一个是下面图表的某种表示形式:
第二种情况是一个图包含一个“无限”循环的最简单情况 {a->b, b->a}
要求
- 不存在类似"无限循环"的事情,当找到一个"无限循环"时,将有一个最大阈值(全局变量)来指示何时停止围绕这些"伪无限循环"进行循环
- 所有图节点都能创建循环,但是会存在一个特殊节点叫做
Repeat,你可以在其中指定循环迭代的次数 - 我发布的上面的mcve是遍历算法的迭代版本,不知道如何处理循环图。理想情况下,解决方案也应该是迭代的,但是如果存在更好的递归解决方案,那就太棒了
- 我们在这里谈论的数据结构实际上不应该被称为"有向无环图",因为在这种情况下,每个节点都有其子节点排序,而在图中节点连接没有顺序。
- 编辑器中可以任意连接任何内容。您将能够执行任何块组合,唯一的限制是执行计数器,如果您制作了永不结束的循环或太多迭代,则会溢出。
- 该算法将像上面的代码片段一样保留开始/中间/后续节点的方法执行
问题
请问是否有解决方案可以遍历无限/有限循环?
参考资料
如果现在问题还不清楚,您可以在文章中阅读更多关于这个问题的内容,整个想法是使用遍历算法来实现类似于该文章中展示的工具。
这里是一张屏幕截图,展示了我想要遍历和运行的这种数据结构的全部功能: