我想在预测模型中使用交叉验证。我想将我的数据保留20%作为测试集,并使用其余的数据来使用交叉验证拟合我的模型。
具体操作如下:
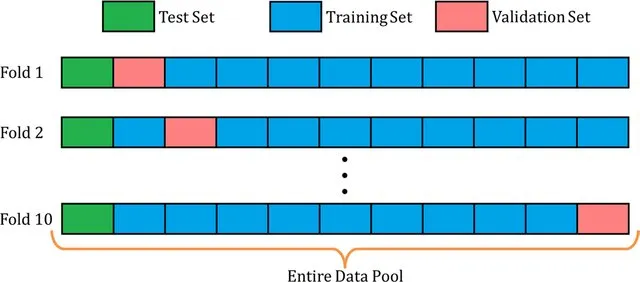
作为一个机器学习模型,我想使用随机森林和LightGBM。
from sklearn.ensemble import RandomForestRegressor
random_forest = RandomForestRegressor (n_estimators=1400, max_depth=80, max_features='sqrt',
min_samples_leaf=1, min_samples_split=5,
random_state=1, verbose=1, n_jobs=-1)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(random_forest, X_train, y_train, cv=5, scoring = 'r2')
它给出了结果,但我想预测X_test数据的y值。你能帮我吗?之后,我还会创建一个LightGBM模型。
model,然后你可以使用model.predict(x_train),它会返回一个预测列表。 - undefined