我发布这篇文章,尽管已经有很多关于这个问题的帖子了。我不想发表答案,因为它不起作用。这篇文章的答案 (在具有重复项的所有可能排列列表中查找给定字符串的排名) 对我没有用。
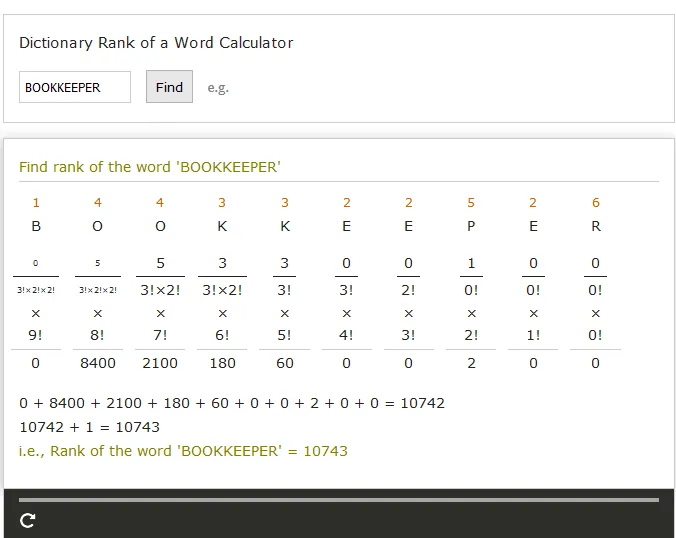
所以我尝试了这个(这是我抄袭的代码和处理重复的尝试的汇编)。不重复的情况下可以正常工作。 BOOKKEEPER 生成83863,而不是期望的10743。
(阶乘函数和字母计数数组“repeats”正在正确运行。我没有发布是为了节省空间。)
所以我尝试了这个(这是我抄袭的代码和处理重复的尝试的汇编)。不重复的情况下可以正常工作。 BOOKKEEPER 生成83863,而不是期望的10743。
(阶乘函数和字母计数数组“repeats”正在正确运行。我没有发布是为了节省空间。)
while (pointer != length)
{
if (sortedWordChars[pointer] != wordArray[pointer])
{
// Swap the current character with the one after that
char temp = sortedWordChars[pointer];
sortedWordChars[pointer] = sortedWordChars[next];
sortedWordChars[next] = temp;
next++;
//For each position check how many characters left have duplicates,
//and use the logic that if you need to permute n things and if 'a' things
//are similar the number of permutations is n!/a!
int ct = repeats[(sortedWordChars[pointer]-64)];
// Increment the rank
if (ct>1) { //repeats?
System.out.println("repeating " + (sortedWordChars[pointer]-64));
//In case of repetition of any character use: (n-1)!/(times)!
//e.g. if there is 1 character which is repeating twice,
//x* (n-1)!/2!
int dividend = getFactorialIter(length - pointer - 1);
int divisor = getFactorialIter(ct);
int quo = dividend/divisor;
rank += quo;
} else {
rank += getFactorialIter(length - pointer - 1);
}
} else
{
pointer++;
next = pointer + 1;
}
}