当我处理复杂的R项目时,我的脚本很快就会变得冗长和混乱。
有哪些实践方法可以采用,以便我的代码始终易于使用?我考虑到以下几点:
- 在源文件中放置函数的位置
- 何时将某些内容拆分到另一个源文件中
- 主文件应包含什么内容
- 使用函数作为组织单元(鉴于R使全局状态访问困难,是否值得这样做)
- 缩进/换行的做法。
- 像 ( 这样的符号应该如何处理?
- 将 )} 这样的内容放在1或2行上?
基本上,你对组织大型R脚本有什么经验之谈?
当我处理复杂的R项目时,我的脚本很快就会变得冗长和混乱。
有哪些实践方法可以采用,以便我的代码始终易于使用?我考虑到以下几点:
基本上,你对组织大型R脚本有什么经验之谈?
R CMD check进行很多健全性检查source()适用于非常短的代码片段。其他所有内容都应该在软件包中 - 即使您不打算将其发布为内部存储库的内部软件包。我喜欢将不同的功能放在它们自己的文件中。
但我不喜欢 R 的软件包系统。 它相当难使用。
我更喜欢轻量级的替代方案,将文件的函数放置在一个环境中(其他语言称为“命名空间”)并附加它。例如,我制作了一个名为“util”的函数组:
util = new.env()
util$bgrep = function [...]
util$timeit = function [...]
while("util" %in% search())
detach("util")
attach(util)
所有的代码都在util.R文件中。当你调用它时,会得到一个名为“util”的环境,因此你可以调用util$bgrep()等函数;但更重要的是,attach()调用使得直接调用bgrep()等函数也能正常工作。如果没有将所有这些函数放在自己的环境中,它们将会污染解释器的顶层命名空间(即ls()显示的那个命名空间)。
我试图模拟Python的系统,即每个文件都是一个模块。这样会更好,但这种方法似乎也可以。
sys.source:
MyEnv <- attach(NULL, name=s_env); sys.source(file, MyEnv)。我甚至在启动时声明(在它自己的环境中!)一个名为 sys.source2 的函数,它将查找是否已经存在同名的环境,并将其替换而不是创建新的。这使得添加个人函数变得快速、简单和有点有组织 :-) - Antoine Lizée这可能听起来有些显而易见,特别是对于程序员来说,但以下是我如何考虑代码的逻辑和物理单位。
我不知道这是否适用于你,但当我在R中工作时,很少会一开始就想着写一个大而复杂的程序。我通常从一个脚本开始,并将代码分成逻辑可分离的单元,通常使用函数。数据操作和可视化代码都放置在自己的函数中等等。这样的函数被分组放在文件的一个部分(例如,在顶部进行数据操作,然后是可视化等)。最终,您要考虑如何使脚本更易于维护并降低缺陷率。
您将函数粒度设置得多细/粗将会有所不同,并且有各种经验法则:例如15行代码,或“函数应负责执行一个任务,该任务由其名称确定”等。结果因人而异。由于R不支持按引用调用,我通常在涉及传递数据框或类似结构的情况下不会将函数设置得太细粒度。但这可能是我刚开始使用R时犯了一些愚蠢的性能错误后的过度补偿。
何时将逻辑单元提取到它们自己的物理单元中(例如源文件和更大的分组,例如软件包)?我有两种情况。首先,如果文件太大,并且在逻辑上不相关的单元之间来回滚动会让人烦恼。其次,如果我有其他程序可以重用的函数。我通常会将一些分组单元(例如数据操作功能)放入单独的文件中。然后我可以从任何其他脚本中调用此文件。
如果您要部署函数,则需要开始考虑软件包。出于各种原因(简要而言:组织文化更喜欢其他语言,对性能的担忧,GPL等),我不会在生产中或供他人重用时部署R代码。另外,我倾向于不断改进和添加源文件集合,并且在进行更改时不想处理软件包。因此,您应该查看其他与软件包相关的答案,例如Dirk的答案,以获取更多详细信息。
最后,我认为你的问题并不一定只适用于 R。我强烈推荐阅读 Steve McConnell 的 Code Complete,其中包含了许多关于这类问题和编程实践的智慧。
我的简洁回答:
我认为R在生产中的使用越来越多,因此对可重用代码的需求比以前更大。我发现解释器比以前更加稳定。毫无疑问,R比C慢100-300倍,但通常瓶颈集中在几行代码上,这些代码可以委托给C / C ++处理。如果将R在数据操作和统计分析方面的优势委派给另一种语言,那么这将是一个错误。在这些情况下,性能惩罚低,而且无论如何都值得节省开发工作量。如果只考虑执行时间,我们都应该写汇编语言。
我一直想弄清楚如何编写软件包,但一直没有投入时间。对于我的每个小项目,我都将所有低级别的函数放在一个名为'functions/'的文件夹中,并将它们导入到一个我明确创建的单独命名空间中。
如果环境不存在,以下代码将创建一个名为"myfuncs"的环境(使用attach),并使用sys.source将'functions/'目录中的.R文件中包含的函数填充其中。我通常将这些行放在我的主要脚本的顶部,该脚本用于“用户界面”,从中调用高级函数(调用低级函数)。
if( length(grep("^myfuncs$",search()))==0 )
attach("myfuncs",pos=2)
for( f in list.files("functions","\\.r$",full=TRUE) )
sys.source(f,pos.to.env(grep("^myfuncs$",search())))
当您进行更改时,您始终可以使用相同的代码行重新获取资源,或者使用类似以下内容的东西
evalq(f <- function(x) x * 2, pos.to.env(grep("^myfuncs$",search())))
为了评估你创建的环境中的添加/修改,这种方法可能有些笨拙,但避免了过于正式(但如果机会允许的话,我鼓励使用软件包系统-希望未来会迁移到那个方向)。
至于编码约定,下面链接是我见过的唯一与美学相关的内容(我喜欢它们,松散地遵循,但在R中我不使用太多花括号):
http://www1.maths.lth.se/help/R/RCC/
关于使用[,drop=FALSE]和<-作为赋值操作符的其他“约定”通常在useR!会议的各种演示文稿中提出,但我认为这些都不是严格规定(虽然[,] drop = FALSE对于您不确定预期输入的程序非常有用)。
我支持使用软件包。 我承认在没有必要时(即发布时)编写手册和示例文档的能力很差,但这是一种非常方便的方式来捆绑源代码。 此外,如果您认真维护自己的代码,Dirk提出的所有观点都会发挥作用。
我也同意。使用package.skeleton()函数开始编写代码。即使你认为你的代码可能永远不会再次运行,它可能会激励你创建更通用的代码,以后可以节省时间。
至于访问全局环境,使用<<-操作符很容易,但是这样做是不被鼓励的。
我还没有学会如何写包,所以我一直通过引用子脚本来组织代码。这与编写类相似但不那么复杂。虽然它在程序上不够优雅,但我发现随着时间的推移,我可以逐步构建分析过程。一旦我有一个有效的大段代码,我通常会将其移动到另一个脚本中并进行引用,因为它将使用工作区对象。也许我需要从几个来源导入数据,对它们进行排序并找到交集。我可能会将该部分放入另一个脚本中。然而,如果您想要为其他人分发您的“应用程序”,或者它使用了某些交互式输入,则包可能是一个很好的选择。作为研究人员,我很少需要分发我的分析代码,但我经常需要增强或调整它。
rsuite构建R项目的新范例。rsuite的创建者或开发者。make 来管理底层的R项目; 你可以在顶层使用R脚本。让我给你展示一下。当你创建一个rsuite主项目时,你会得到这样的文件夹结构:
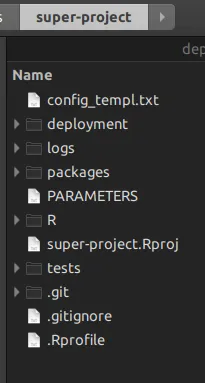
文件夹R是您放置项目管理脚本的地方,这些脚本将替换make。
文件夹packages是rsuite保存组成超级项目的所有软件包的文件夹。您还可以复制粘贴无法从Internet访问的软件包,rsuite也会构建它们。
文件夹deployment是rsuite将写入在软件包的DESCRIPTION文件中指定的所有软件包二进制文件的位置。因此,这使得您的项目完全可重现。
rsuite适用于所有操作系统的客户端。我已经测试过了。但是您也可以将其安装为RStudio的addin。
rsuite还允许您在其自己的conda文件夹中构建隔离的conda安装程序。这不是一个环境,而是来自您计算机上Anaconda衍生的物理Python安装程序。这与R的SystemRequirements一起使用,您可以从任何conda渠道安装所需的所有Python软件包。
您还可以创建本地存储库,在离线时或想更快地构建整个项目时拉取R软件包。
如果需要,您还可以将R项目构建为zip文件并与同事共享。只要您的同事安装了相同版本的R,它就可以运行。
另一种选择是在Ubuntu、Debian或CentOS中构建整个项目的容器。因此,与其共享已构建的zip文件,您可以共享整个Docker容器,其中包含准备好运行的项目。
rsuite进行完全可重复性的实验,并避免依赖全局环境中安装的软件包。这是错误的,因为一旦您安装软件包更新,项目往往就会停止工作,特别是那些具有特定参数函数调用的软件包。bookdown电子书进行实验。我从来没有幸运地拥有一本可以经受时间考验超过六个月的bookdown。所以,我将原始的bookdown项目转换为遵循rsuite框架的项目。现在,我不必担心更新我的全局R环境,因为该项目在deployment文件夹中有自己的一套软件包。rsuite的方式。一个掌控项目的主项目,所有子项目和软件包都由主项目控制。这确实改变了您使用R编程的方式,使您更加高效。rTorch的新软件包。这在很大程度上得益于rsuite;它让您思考并且做得更好。
不过,我有一个建议。学习 rsuite 并不容易。因为它提供了一种创建 R 项目的新方式,所以感觉很困难。不要在第一次尝试时就灰心丧气,继续攀登这座山坡,直到成功。这需要你对操作系统和文件系统有先进的知识。
我希望有一天,RStudio 可以让我们像 rsuite 一样从菜单中生成编排项目,那将是非常棒的。
链接:
R语言适合交互式使用和小型脚本,但我不会在大型程序中使用它。对于大部分编程任务,我会使用主流语言,并在R接口中进行封装。
ProjectTemplate包。 - ctbrown