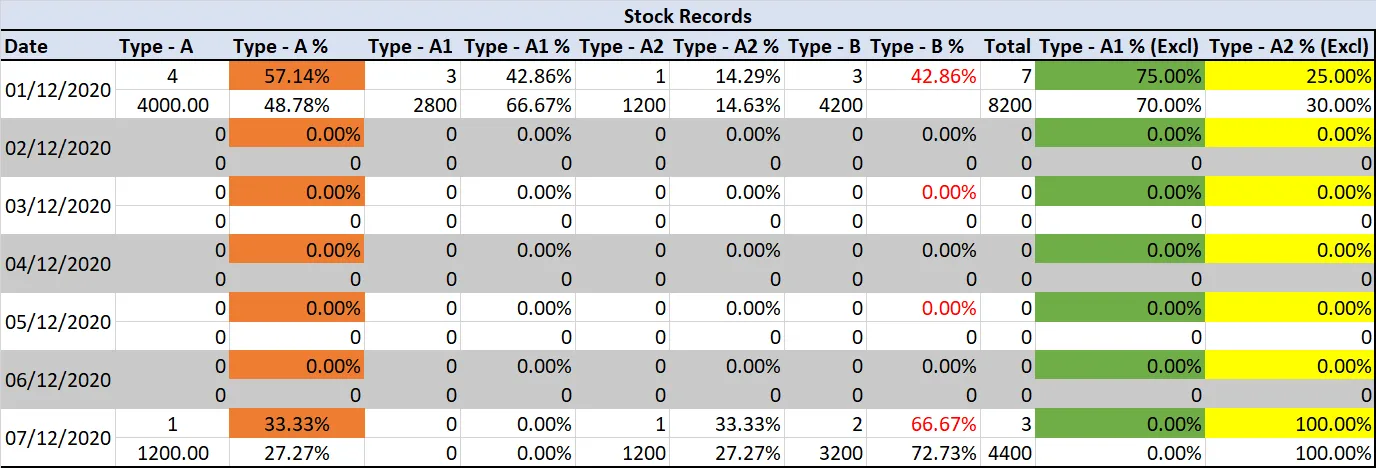
这里是一个
data.table 的解决方案。我尝试避免手动计算,而是想出了一种基于长宽转换的解决方案。
以下是我的解决方案,其中包含了详细的步骤说明:
library(lubridate)
library(data.table)
dt <- setDT(dt)
dt[,Date := date(Date)]
dt[,type := fifelse(Type == "SS_RT",fifelse(Remark == "AT_1_O","A1","A2"),"B")]
df2 <- rbind(dcast(data = dt,Date~type ,value.var = "Price",fill = 0)[,linetype := "count"],
dcast(data = dt,Date~type ,value.var = "Price",fill = 0,fun.aggregate = sum)[,linetype := "value"])
df2[,tot := rowSums(.SD),.SDcols = c("A1","A2","B")]
df2[,A := A1+A2]
cols <- c("A","A1","A2","B")
df2[,paste0(cols,"_pc") := lapply(.SD,function(x) round(x/tot*100) ),.SDcols = cols]
cols <- c("A1","A2")
df2[,paste0(cols,"_exc") := lapply(.SD,function(x) round(x/(A1+A2)*100) ),.SDcols = cols]
df2 <- merge(CJ(Date = seq(min(dt$Date),max(dt$Date),1),linetype = c("count","value")),
df2,all = T,by = c("Date","linetype"))
df2[is.na(df2)] <- 0
df2[,linetype := NULL]
df2
Date A1 A2 B tot A A_pc A1_pc A2_pc B_pc A1_exc A2_exc
1: 2020-12-01 3 1 3 7 4 57 43 14 43 75 25
2: 2020-12-01 3800 1200 4200 9200 5000 54 41 13 46 76 24
3: 2020-12-02 0 0 0 0 0 0 0 0 0 0 0
4: 2020-12-02 0 0 0 0 0 0 0 0 0 0 0
5: 2020-12-03 0 0 0 0 0 0 0 0 0 0 0
6: 2020-12-03 0 0 0 0 0 0 0 0 0 0 0
7: 2020-12-04 0 0 0 0 0 0 0 0 0 0 0
8: 2020-12-04 0 0 0 0 0 0 0 0 0 0 0
9: 2020-12-05 0 0 0 0 0 0 0 0 0 0 0
10: 2020-12-05 0 0 0 0 0 0 0 0 0 0 0
11: 2020-12-06 0 0 0 0 0 0 0 0 0 0 0
12: 2020-12-06 0 0 0 0 0 0 0 0 0 0 0
13: 2020-12-07 0 1 2 3 1 33 0 33 67 0 100
14: 2020-12-07 0 1600 3200 4800 1600 33 0 33 67 0 100
首先,我根据您的规则创建了type变量:
dt[,Date := date(Date)]
dt[,type := fifelse(Type == "SS_RT",fifelse(Remark == "AT_1_O","A1","A2"),"B")]
我们知道
A只是由
A1和
A2组成的。这使我能够将表格转换为宽度格式。我需要进行两次转换:一次进行计数,一次按类型求和。
dcast(data = dt,Date ~ type ,value.var = "Price",fill = 0)
Date A1 A2 B
1: 2020-12-01 3 1 3
2: 2020-12-07 0 1 2
在这里,我统计每种类型的出现次数,因为它使用默认聚合:lenght。
如果我使用sum作为聚合函数:
dcast(data = dt,Date~type ,value.var = "Price",fill = 0,fun.aggregate = sum)
Date A1 A2 B
1: 2020-12-01 3800 1200 4200
2: 2020-12-07 0 1600 3200
我添加了一个linetype变量,这将有助于我在之后添加缺失的日期(我使用它来使每个日期保持两条线)。
我绑定这两个,得到:
Date A1 A2 B linetype
1: 2020-12-01 3 1 3 count
2: 2020-12-07 0 1 2 count
3: 2020-12-01 3800 1200 4200 value
4: 2020-12-07 0 1600 3200 value
我会计算A和总计:
df2[,tot := rowSums(.SD),.SDcols = c("A1","A2","B")]
df2[,A := A1+A2]
我接下来会使用lapply和一个指定要转换的列的向量来计算百分比(_pc)和排除变量(_exc)。我使用fifelse来避免除以0:
cols <- c("A","A1","A2","B")
df2[,paste0(cols,"_pc") := lapply(.SD,function(x) round(x/tot*100) ),.SDcols = cols]
cols <- c("A1","A2")
df2[,paste0(cols,"_exc") := lapply(.SD,function(x) round(x/(A1+A2)*100) ),.SDcols = cols]
Date A1 A2 B linetype tot A A_pc A1_pc A2_pc B_pc A1_exc A2_exc
1: 2020-12-01 3 1 3 count 7 4 57 43 14 43 75 25
2: 2020-12-01 3800 1200 4200 value 9200 5000 54 41 13 46 76 24
3: 2020-12-07 0 1 2 count 3 1 33 0 33 67 0 100
4: 2020-12-07 0 1600 3200 value 4800 1600 33 0 33 67 0 100
然后,我通过将所有linetype和Date的组合进行合并,并保留所有行来添加缺失的日期。我使用CJ函数创建一个包含两个变量所有组合的data.table:
CJ(Date = seq(min(dt$Date),max(dt$Date),1),linetype = c("count","value"))
Date linetype
1: 2020-12-01 count
2: 2020-12-01 value
3: 2020-12-02 count
4: 2020-12-02 value
5: 2020-12-03 count
6: 2020-12-03 value
7: 2020-12-04 count
8: 2020-12-04 value
9: 2020-12-05 count
10: 2020-12-05 value
11: 2020-12-06 count
12: 2020-12-06 value
13: 2020-12-07 count
14: 2020-12-07 value
然后,用0替换缺失值并去掉linetype变量。
接下来可以使用setcolorder重新排列列,使用kabbleExtra(见这里)生成html输出。
您也可以使用dplyr进行相同操作,使用pivot_wider转换为宽表格,使用mutate_all代替lapply(.SD,...)进行计算,使用expand.grid代替CJ生成缺失日期的表格。