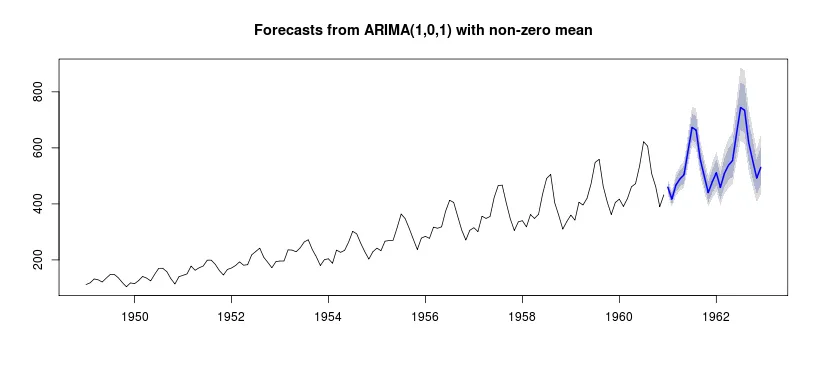
你好,我使用预测包来进行时间序列预测。我想知道如何在最终的预测图中取消对数转换。使用预测包时,我不知道如何取消我的序列的对数转换。以下是一个示例:
library(forecast)
data <- AirPassengers
data <- log(data) #with this AirPassengers data not nessesary to LOG but with my private data it is...because of some high picks...
ARIMA <- arima(data, order = c(1, 0, 1), list(order = c(12,0, 12), period = 1)) #Just a fake ARIMA in this case...
plot(forecast(ARIMA, h=24)) #but my question is how to get a forecast plot according to the none log AirPassenger data
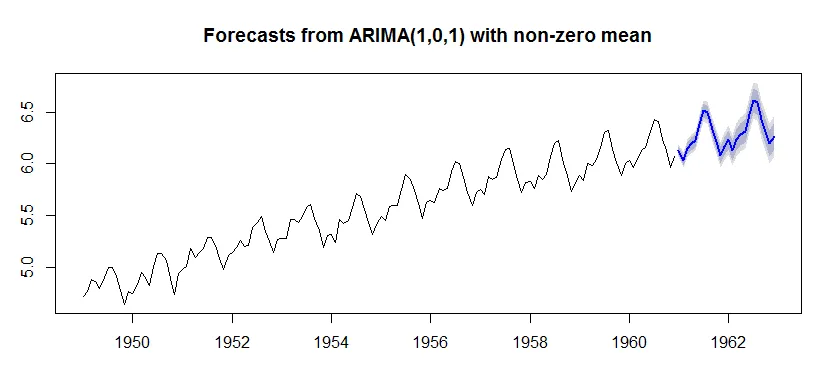
因此,该图像已记录。我希望使用非对数数据拥有相同的ARIMA模型。