我有一段Python代码,它的输出是一个大小为 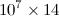 的矩阵,其所有元素都是
的矩阵,其所有元素都是
的矩阵,其所有元素都是 float 类型。如果我将其保存为扩展名为 .dat 的文件,文件大小约为 500 MB。我了解到使用 h5py 可以显著减小文件大小。那么,假设我有名为 A 的 2D numpy 数组。如何将其保存到一个 h5py 文件中?
另外,如何读取相同的文件并将其作为 numpy 数组放入不同的代码中,因为我需要对数组进行操作?
.dat扩展名来保存它的? - jorgecanp.savetxt("output.dat",A,'%10.8e')。 - lovespeednp.save('output.dat', A)将其保存为二进制格式(速度更快,占用空间更少)。 - jorgecatxt和解包参数即可。 - jorgecah5py不会创建比np.save更小的文件吗?对于问题中给定大小的数组,h5py是否比np.save更快? - abcd