我正在尝试使用维基百科文本数据训练word2vec模型,下面是我使用的代码。
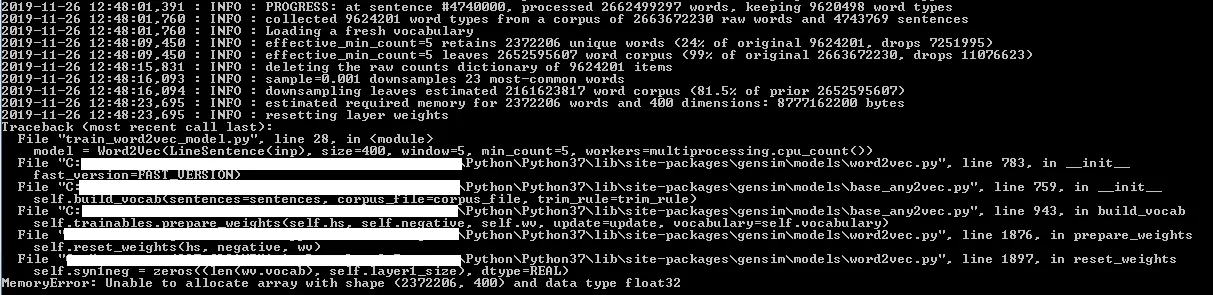
但是在程序运行20分钟后,我遇到了以下错误:错误信息。
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 3:
print (globals()['__doc__'])
sys.exit(1)
inp, outp = sys.argv[1:3]
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count())
# trim unneeded model memory = use (much) less RAM
model.init_sims(replace=True)
model.save(outp)
但是在程序运行20分钟后,我遇到了以下错误:错误信息。
{kind=link}