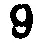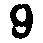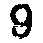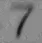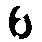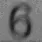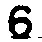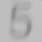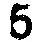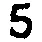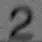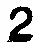我应该如何处理这张模糊的图片,以使数字更加清晰?在之前的一篇文章中,我尝试了自适应阈值处理模糊图像(左图),结果导致数字变形且不连续(右图):

从那时起,我尝试使用形态学闭运算来使图像的亮度均匀,如this post所述:


- 我必须手动选择阈值。虽然闭合操作可以使亮度均匀,但其他图像的亮度水平可能会不同。
- 图像的不同部分在阈值水平上略有变化会更好。例如,左上角的9和7出现了部分褪色,应该有一个较低的阈值,而一些6已经融合成8,应该有一个较高的阈值。

编辑:尝试使用椭圆核来开启此帖子右上角的阈值图像,remi建议使用suggested。但是效果并不太好。使用椭圆核时,只有3x3足够小,可以避免完全抹掉图像,即使如此,数字仍然会出现显著的断裂:


这是我改编后的代码,可以原地过滤:
private void wiener(Mat input, int nRows, int nCols) { // I tried nRows=5 and nCols=5
Mat localMean = new Mat(input.rows(), input.cols(), input.type());
Mat temp = new Mat(input.rows(), input.cols(), input.type());
Mat temp2 = new Mat(input.rows(), input.cols(), input.type());
// Create the kernel for convolution: a constant matrix with nRows rows
// and nCols cols, normalized so that the sum of the pixels is 1.
Mat kernel = new Mat(nRows, nCols, CvType.CV_32F, new Scalar(1.0 / (double) (nRows * nCols)));
// Get the local mean of the input. localMean = convolution(input, kernel)
Imgproc.filter2D(input, localMean, -1, kernel, new Point(nCols/2, nRows/2), 0);
// Get the local variance of the input. localVariance = convolution(input^2, kernel) - localMean^2
Core.multiply(input, input, temp); // temp = input^2
Imgproc.filter2D(temp, temp, -1, kernel, new Point(nCols/2, nRows/2), 0); // temp = convolution(input^2, kernel)
Core.multiply(localMean, localMean, temp2); //temp2 = localMean^2
Core.subtract(temp, temp2, temp); // temp = localVariance = convolution(input^2, kernel) - localMean^2
// Estimate the noise as mean(localVariance)
Scalar noise = Core.mean(temp);
// Compute the result. result = localMean + max(0, localVariance - noise) / max(localVariance, noise) * (input - localMean)
Core.max(temp, noise, temp2); // temp2 = max(localVariance, noise)
Core.subtract(temp, noise, temp); // temp = localVariance - noise
Core.max(temp, new Scalar(0), temp); // temp = max(0, localVariance - noise)
Core.divide(temp, temp2, temp); // temp = max(0, localVar-noise) / max(localVariance, noise)
Core.subtract(input, localMean, input); // input = input - localMean
Core.multiply(temp, input, input); // input = max(0, localVariance - noise) / max(localVariance, noise) * (input - localMean)
Core.add(input, localMean, input); // input = localMean + max(0, localVariance - noise) / max(localVariance, noise) * (input - localMean)
}