我不知道是否有帮助函数,但如果你想查看所有过滤器,可以通过一些 tf.transpose 的花式使用将它们全部打包到一个图像中。
因此,如果您有一个张量,它是 images x ix x iy x channels。
>>> V = tf.Variable()
>>> print V.get_shape()
TensorShape([Dimension(-1), Dimension(256), Dimension(256), Dimension(32)])
所以在这个例子中,
ix = 256,
iy = 256,
channels = 32。首先切掉一个图像,然后移除
image维度。
V = tf.slice(V,(0,0,0,0),(1,-1,-1,-1))
V = tf.reshape(V,(iy,ix,channels))
接下来在图像周围添加几个像素的零填充
ix += 4
iy += 4
V = tf.image.resize_image_with_crop_or_pad(image, iy, ix)
然后进行重新塑形,使得32个通道变成4x8个通道,我们称之为cy=4和cx=8。
V = tf.reshape(V,(iy,ix,cy,cx))
现在是比较棘手的部分。 tf 似乎按照 C-order 返回结果,这是 numpy 的默认顺序。
当前顺序,如果展开后,会先列出第一个像素的所有通道(迭代 cx 和 cy),然后再列出第二个像素的通道(增加 ix)。在增加到下一行 (iy) 之前横跨像素行 (ix)。
我们希望排列图像的顺序是按网格形式排列。所以您要先横跨图像的一行 (ix),然后沿着通道的行 (cx) 步进,当您到达通道行的末尾时,跳转至图像的下一行 (iy),当您用完所有行时,则递增到下一个通道行 (cy)。因此:
V = tf.transpose(V,(2,0,3,1))
就我个人而言,我更喜欢使用 np.einsum 进行炫酷的转置操作,因为它更易读,但是它目前还没有被纳入 tf 中,详情请参见 这里。
newtensor = np.einsum('yxYX->YyXx',oldtensor)
无论如何,现在像素顺序已经正确,我们可以安全地将其压平成2D张量:
V = tf.reshape(V,(1,cy*iy,cx*ix,1))
尝试在其中应用tf.image_summary函数,你应该会得到一个小图像的网格。
下面是按照这里的所有步骤所得到的图像。

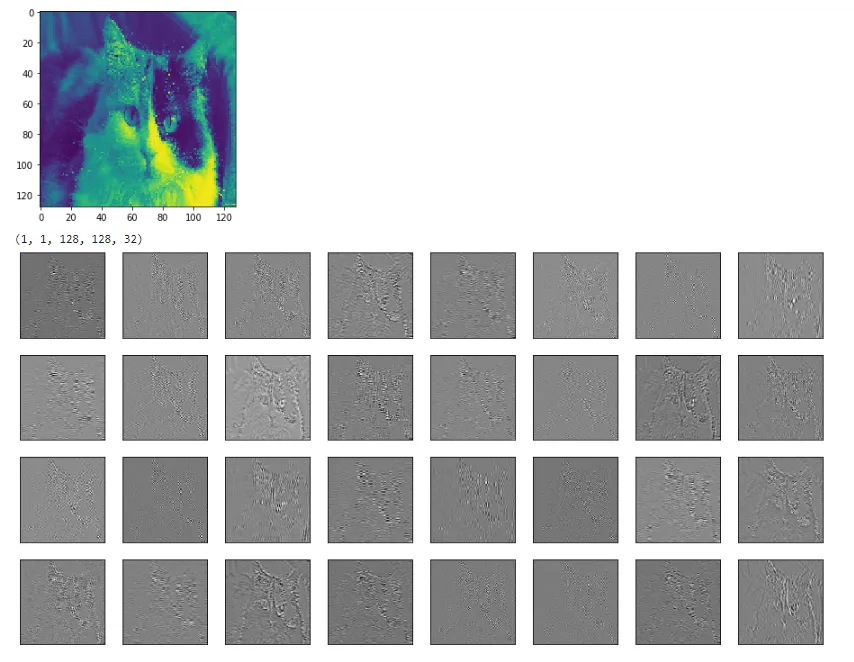
tf.image_summary,因此您需要重新调整形状V=tf.reshape(V,(1,4*256,8*256,1))。 - jeandutV = tf.image.resize_image_with_crop_or_pad(image, iy, ix)中,第一个参数应该是 V 而不是 image 吗?我看不出来 image 是从哪里来的。 - BobbyG