我正在开发一个使用机器学习来预测图像相似度的图像复制库。在此过程中,我们使用均方根误差(Root Mean Square)计算两个图像之间的相似性(我不会进一步解释)。执行此功能的函数如下所示。
# Function that calulates the mean squared error (mse) between two image matrices
def _mse(imageA, imageB):
err = np.sum((imageA.astype("float") - imageB.astype("float")) ** 2)
err /= float(imageA.shape[0] * imageA.shape[1])
return err
我测试了包含5K张图片的文件夹,我的模型效果很好,但是耗时太长。因此,我决定重构代码并将所有张量存储在数据库中。为什么?
如果我将所有图像的张量存储在数据库中,然后使用它来查询即将到来的图像张量,我会很快得到结果。反复遍历所有图像+将一个图像RMS与其他图像匹配将导致许多组合,这需要时间。
解决方案
如果我将所有张量(列表或数组)存储在Postgres数据库中,那么我可以轻松地查询它们与RMS相关的内容,以一次性获取所有图像,而不是遍历它们并找出重复项。
我需要您的帮助来找出是否有任何方法可以查询Postgres以获得最接近RMS的图像
类似于以下内容:
SELECT ID_PARTNER, ID_ACCOUNT
, SQRT(Avg( POWER(Act_F_1 - Pred_F_1 , 2) ) ) as feature_1_rmse
FROM ...
GROUP BY ID_PARTNER, ID_ACCOUNT
类似问题:如何在直接从表格获取数据时获取RMSE分数?编写查询以实现该目标
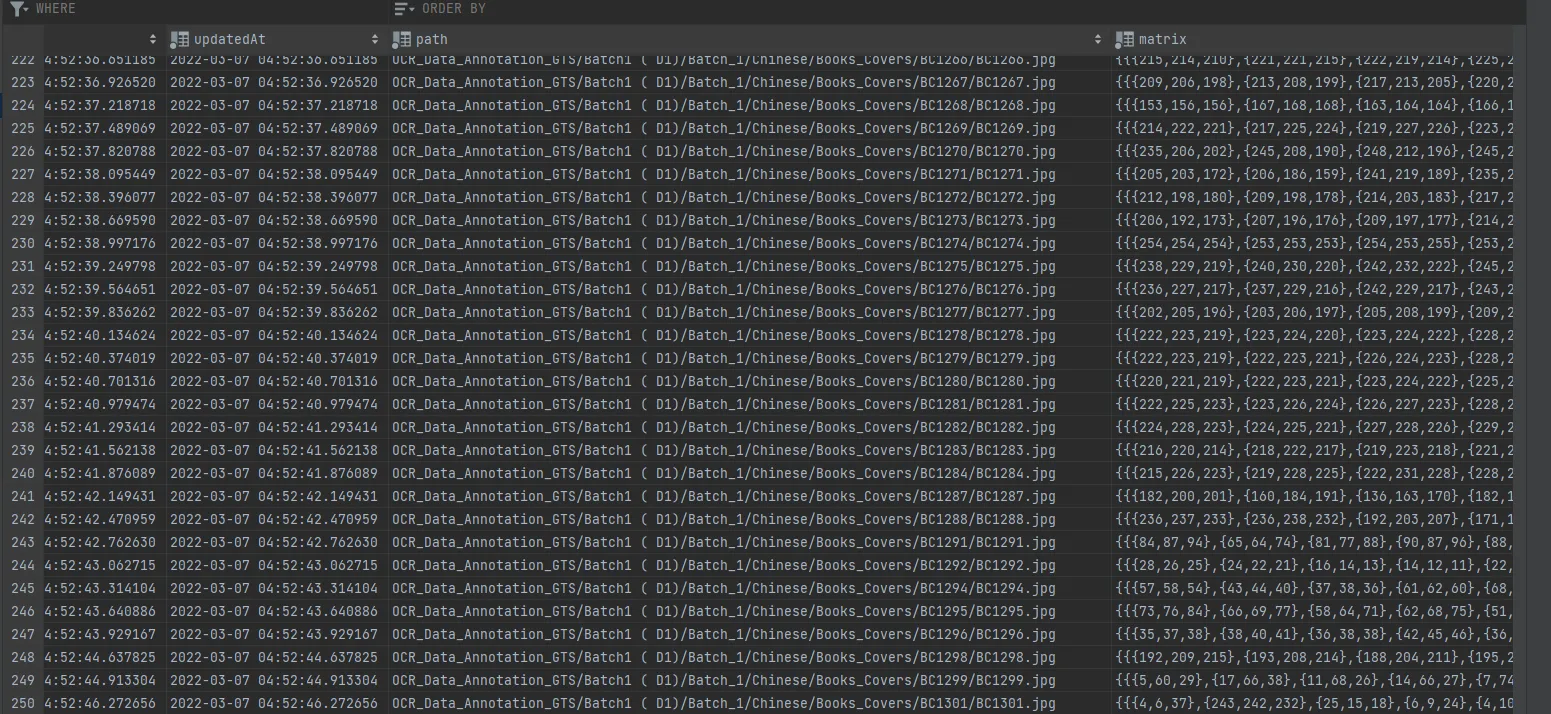
这是数据库的样子