我有以下数据:
key German
0 0:- Profile 1
1 1:- Archetype Realist*in
2 2:- RIASEC Code: R- Realistic
3 3:- Subline Deine Stärke? Du bleibst dir selber treu.
4 4:- Copy Dein Erfolg basiert auf deiner praktischen Ver...
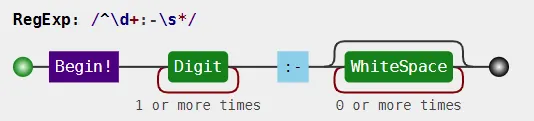
在“键”列中,我希望删除后面的数字、冒号和短划线。这个顺序总是相同的(从左边开始)。因此,对于第一行,我想删除“0:-”,只留下“Profile 1”。我正在努力查找正确的正则表达式来实现我的要求。最初,我尝试了以下内容:
df_json['key'] = df_json['key'].map(lambda x: x.strip(':- ')[1])
然而,这种方法过于严格,因为字段中可能有多个单词。
我想使用pd.Series.str.replace(),但我无法找到正确的正则表达式来实现所需的结果。任何帮助将不胜感激。