作为一个
OpenMP 和 Rcpp 的性能测试,我想检查使用最简单直接的 Rcpp+OpenMP 实现在 R 中计算 Mandelbrot 集合的速度有多快。目前我所做的是:#include <Rcpp.h>
#include <omp.h>
// [[Rcpp::plugins(openmp)]]
using namespace Rcpp;
// [[Rcpp::export]]
Rcpp::NumericMatrix mandelRcpp(const double x_min, const double x_max, const double y_min, const double y_max,
const int res_x, const int res_y, const int nb_iter) {
Rcpp::NumericMatrix ret(res_x, res_y);
double x_step = (x_max - x_min) / res_x;
double y_step = (y_max - y_min) / res_y;
int r,c;
#pragma omp parallel for default(shared) private(c) schedule(dynamic,1) collapse(2)
for (r = 0; r < res_y; r++) {
for (c = 0; c < res_x; c++) {
double zx = 0.0, zy = 0.0, new_zx;
double cx = x_min + c*x_step, cy = y_min + r*y_step;
int n = 0;
for (n=0; (zx*zx + zy*zy < 4.0 ) && ( n < nb_iter ); n++ ) {
new_zx = zx*zx - zy*zy + cx;
zy = 2.0*zx*zy + cy;
zx = new_zx;
}
ret(c,r) = n;
}
}
return ret;
}
然后在R中:
library(Rcpp)
sourceCpp("mandelRcpp.cpp")
xlims=c(-0.74877,-0.74872);
ylims=c(0.065053,0.065103);
x_res=y_res=1080L; nb_iter=10000L;
system.time(m <- mandelRcpp(xlims[[1]], xlims[[2]], ylims[[1]], ylims[[2]], x_res, y_res, nb_iter))
# 0.92s
rainbow=c(rgb(0.47,0.11,0.53),rgb(0.27,0.18,0.73),rgb(0.25,0.39,0.81),rgb(0.30,0.57,0.75),rgb(0.39,0.67,0.60),rgb(0.51,0.73,0.44),rgb(0.67,0.74,0.32),rgb(0.81,0.71,0.26),rgb(0.89,0.60,0.22),rgb(0.89,0.39,0.18),rgb(0.86,0.13,0.13))
cols=c(colorRampPalette(rainbow)(100),rev(colorRampPalette(rainbow)(100)),"black") # palette
par(mar=c(0, 0, 0, 0))
system.time(image(m^(1/7), col=cols, asp=diff(ylims)/diff(xlims), axes=F, useRaster=T))
# 0.5s
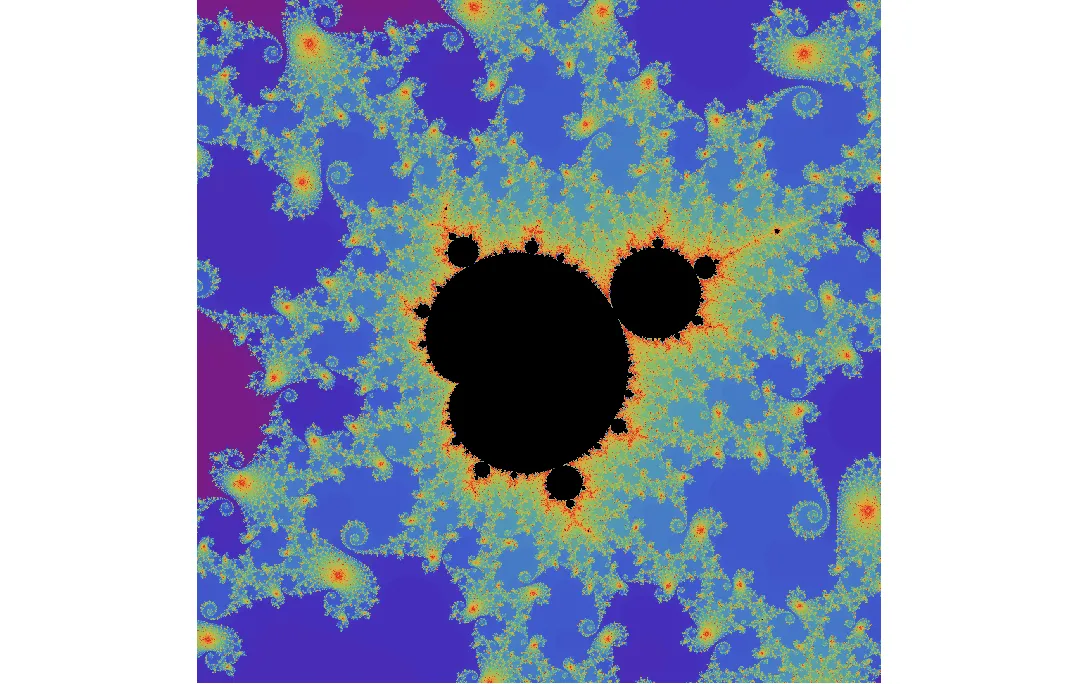
我不确定除了OpenMP多线程之外,是否还有其他明显的速度提升方法可以利用,例如通过simd向量化?(在openmp #pragma中使用simd选项似乎没有任何效果)
首先我的代码一开始崩溃了,但后来我发现通过将ret[r,c] = n;替换为ret(r,c) = n;可以解决这个问题。如下面的答案所建议的使用Armadillo类可以使事情稍微快一点,尽管时间几乎相同。还将x和y翻转,以便在使用image()绘制时呈现正确的方向。使用8个线程速度比向量化的普通R Mandelbrot版本here快约350倍,也比(非多线程)Python/Numba版本here(类似于PyCUDA或PyOpenCL速度)快约7.3倍,所以对此感到非常满意... 现在似乎是R中光栅化/显示的瓶颈....

