我试图通过操作时间来以每分钟为基础重新分配平均空闲时间:
#############################################################
##Reproducible example 1 (n=10):
############################################################# df.in <- structure(list(id = c(31, 46, 60, 57, 44, 04, 18, 55,
22, 5), loc = structure(c(1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L,
3L, 3L), .Label = c("A", "B", "C"), class = "factor"), t.arrive = structure(c(1425197374,
1425197392, 1425197411, 1425198171, 1425198190, 1425196800, 1425197837,
1425198027, 1425197507, 1425198026), class = c("POSIXct", "POSIXt"
), tzone = "UTC"), t.leave = structure(c(1425197409, 1425197531,
1425197555, 1425198171, 1425198296, 1425196992, 1425197865, 1425198028,
1425197512, 1425198026), class = c("POSIXct", "POSIXt"), tzone = "UTC"),
idle = c(35, 139, 144, 0, 106, 192, 28, 1, 5, 0)), .Names = c("id",
"loc", "t.arrive", "t.leave", "idle"), class = c("tbl_df", "tbl",
"data.frame"), row.names = c(NA, -10L))
#############################################################
##Reproducible example 2 (n=100):
#############################################################
> dput(df.in)
structure(list(id = c(78, 93, 107, 84, 104, 91, 71, 66, 189,
182, 92, 209, 96, 84, 50, 103, 182, 183, 74, 132, 101, 78, 88,
93, 48, 107, 82, 72, 182, 83, 66, 91, 104, 50, 71, 96, 103, 74,
182, 101, 132, 84, 78, 88, 93, 107, 83, 182, 48, 66, 96, 51,
75, 65, 102, 80, 106, 63, 156, 51, 75, 79, 67, 65, 85, 94, 89,
106, 69, 80, 79, 67, 69, 52, 105, 94, 73, 95, 100, 76, 55, 99,
60, 69, 53, 86, 52, 105, 90, 64, 95, 73, 63, 100, 76, 51, 99,
53, 75, 52), loc = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L,
6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L), .Label = c("A",
"HPB", "HPS", "B", "OPP-B", "C"), class = "factor"), t.arrive = structure(c(1425197374,
1425197392, 1425197411, 1425197927, 1425198171, 1425198190, 1425198194,
1425198227, 1425198303, 1425198475, 1425198812, 1425198924, 1425199119,
1425199199, 1425199235, 1425199355, 1425199528, 1425199544, 1425199641,
1425199643, 1425199648, 1425199801, 1425199812, 1425200087, 1425200103,
1425200310, 1425200454, 1425200478, 1425200517, 1425200611, 1425200669,
1425201076, 1425201105, 1425201275, 1425201287, 1425201378, 1425201536,
1425201604, 1425201628, 1425201767, 1425201893, 1425202137, 1425202244,
1425202255, 1425202557, 1425202566, 1425202879, 1425202962, 1425203094,
1425203109, 1425203380, 1425196800, 1425196800, 1425197837, 1425198027,
1425198955, 1425199074, 1425199342, 1425199465, 1425199855, 1425199929,
1425199970, 1425200480, 1425200517, 1425200950, 1425201289, 1425201357,
1425201879, 1425202374, 1425202982, 1425202987, 1425203318, 1425197507,
1425198026, 1425198378, 1425198390, 1425198994, 1425199059, 1425199298,
1425199522, 1425199528, 1425199728, 1425200115, 1425200289, 1425200373,
1425200547, 1425200679, 1425200880, 1425200909, 1425201364, 1425201509,
1425201801, 1425201910, 1425202039, 1425202246, 1425202490, 1425202555,
1425202589, 1425203048, 1425203108), class = c("POSIXct", "POSIXt"
), tzone = "UTC"), t.leave = structure(c(1425197409, 1425197531,
1425197555, 1425197927, 1425198171, 1425198296, 1425198194, 1425198315,
1425198411, 1425198553, 1425198818, 1425198924, 1425199119, 1425199219,
1425199235, 1425199359, 1425199528, 1425199558, 1425199652, 1425199734,
1425199648, 1425199801, 1425200028, 1425200198, 1425200240, 1425200364,
1425200492, 1425200619, 1425200610, 1425200910, 1425200859, 1425201100,
1425201302, 1425201275, 1425201467, 1425201393, 1425201569, 1425201704,
1425201805, 1425201951, 1425202057, 1425202262, 1425202370, 1425202255,
1425202667, 1425202840, 1425202913, 1425202990, 1425203094, 1425203109,
1425203380, 1425196992, 1425196800, 1425197865, 1425198028, 1425198984,
1425199149, 1425199356, 1425199466, 1425199902, 1425200051, 1425200286,
1425200783, 1425200845, 1425201125, 1425201586, 1425201640, 1425201879,
1425202377, 1425202986, 1425202987, 1425203318, 1425197512, 1425198026,
1425198378, 1425198486, 1425199021, 1425199078, 1425199325, 1425199558,
1425199810, 1425199939, 1425200118, 1425200305, 1425200485, 1425200782,
1425200894, 1425201065, 1425201111, 1425201364, 1425201623, 1425201857,
1425202015, 1425202039, 1425202404, 1425202671, 1425202651, 1425202834,
1425203105, 1425203198), class = c("POSIXct", "POSIXt"), tzone = "UTC"),
idle = c(35, 139, 144, 0, 0, 106, 0, 88, 108, 78, 6, 0, 0,
20, 0, 4, 0, 14, 11, 91, 0, 0, 216, 111, 137, 54, 38, 141,
93, 299, 190, 24, 197, 0, 180, 15, 33, 100, 177, 184, 164,
125, 126, 0, 110, 274, 34, 28, 0, 0, 0, 192, 0, 28, 1, 29,
75, 14, 1, 47, 122, 316, 303, 328, 175, 297, 283, 0, 3, 4,
0, 0, 5, 0, 0, 96, 27, 19, 27, 36, 282, 211, 3, 16, 112,
235, 215, 185, 202, 0, 114, 56, 105, 0, 158, 181, 96, 245,
57, 90)), class = "data.frame", .Names = c("id", "loc", "t.arrive",
"t.leave", "idle"), row.names = c(NA, -100L))
这里是我要得到的内容:在任何给定分钟内(必须按loc分组),取每个ID贡献的闲置时间之和。然后,取平均值:
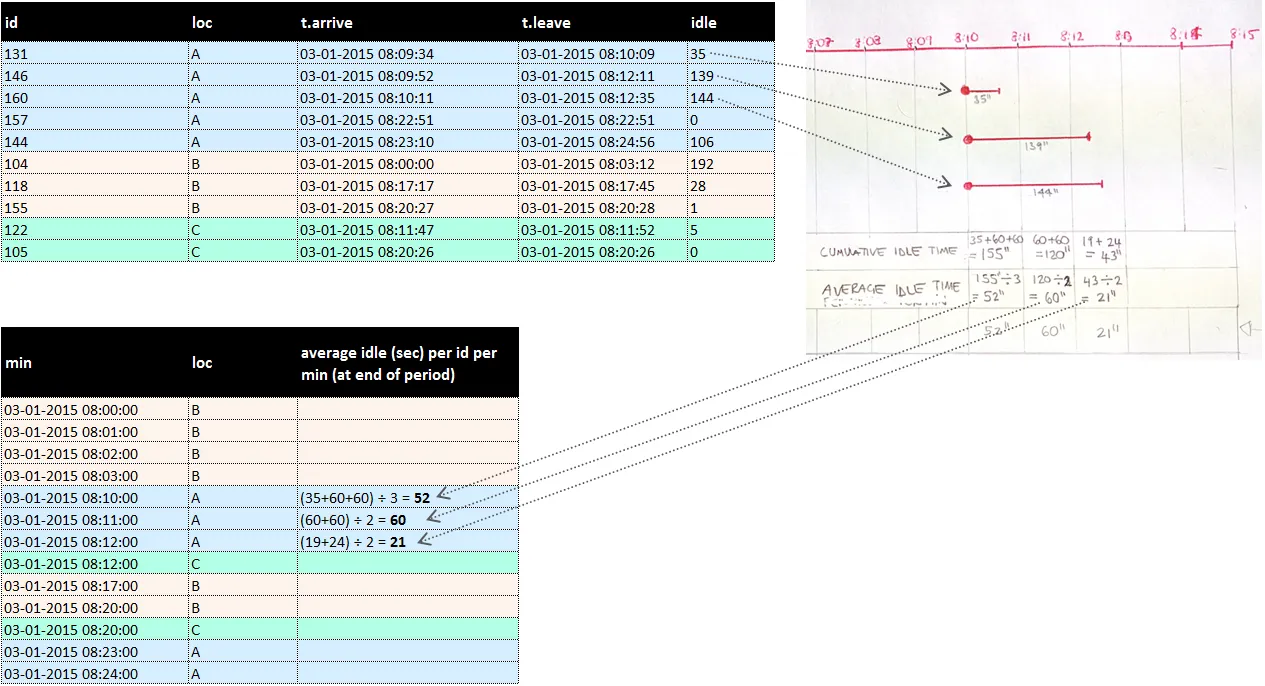 这是我尝试过的方法:
这是我尝试过的方法:## Expand time into 1-min intervals
df.min <- df.in %>%
rownames_to_column() %>%
group_by(rowname) %>%
do(data.frame(min = seq(.$t.arrive, .$t.leave, by = "1 min"),
id = first(.$id),
loc = first(.$loc),
idle.mean = as.numeric(mean(.$idle))
))
## Round Off to 0 seconds to make it more tractable:
df.min$min <- as.POSIXct(round(df.min$min, "mins"))
## Calculate within each minute
df.min <- df.min %>%
group_by(min, loc) %>%
summarise(units.count = n(),
cum.queue.min = sum(idle.mean)/60
)
## Take 1 min average idle time per id
df.min <- as.data.frame(df.min)
df.min <- df.min %>%
mutate(queue.tmean = cum.queue.min / units.count) %>%
select(-units.count, -cum.queue.min) %>%
arrange(min, loc)
loc=A的结果是什么? - David Rubingert.arrive四舍五入到最接近的一分钟(这是我选择的方法),那么8:09就不应该存在,如果确实存在,平均空闲时间应该为“NA”(而不是零)。 - Thomas Speidel