我试图理解一个例子片段,其中使用了PyTorch的转置卷积函数,并且文档在此处链接。在文档中作者写道:“填充参数有效地向输入的两侧添加了 dilation * (kernel_size - 1) - padding 量的零填充。”考虑下面的代码片段,其中输入一个形状为
[1, 1, 4, 4]的样本图像(包含所有元素都为一),并使用参数stride=2和padding=1的ConvTranspose2D操作,其权重矩阵的形状为(1, 1, 4, 4),其中的元素值在1到16范围内(在这种情况下dilation=1并且added_padding = 1*(4-1)-1 = 2)sample_im = torch.ones(1, 1, 4, 4).cuda()
sample_deconv = nn.ConvTranspose2d(1, 1, 4, 2, 1, bias=False).cuda()
sample_deconv.weight = torch.nn.Parameter(
torch.tensor([[[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]]).cuda())
这将产生:
>>> sample_deconv(sample_im)
tensor([[[[ 6., 12., 14., 12., 14., 12., 14., 7.],
[12., 24., 28., 24., 28., 24., 28., 14.],
[20., 40., 44., 40., 44., 40., 44., 22.],
[12., 24., 28., 24., 28., 24., 28., 14.],
[20., 40., 44., 40., 44., 40., 44., 22.],
[12., 24., 28., 24., 28., 24., 28., 14.],
[20., 40., 44., 40., 44., 40., 44., 22.],
[10., 20., 22., 20., 22., 20., 22., 11.]]]], device='cuda:0',
grad_fn=<CudnnConvolutionTransposeBackward>)
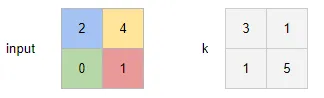
现在我已经看到了没有步幅和填充的简单转置卷积示例。例如,如果输入是一个2x2的图像[[2, 4], [0, 1]],而具有一个输出通道的卷积滤波器是[[3, 1], [1, 5]],那么形状为(1, 1, 3, 3)的结果张量可以看作是下面图片中四个彩色矩阵之和:
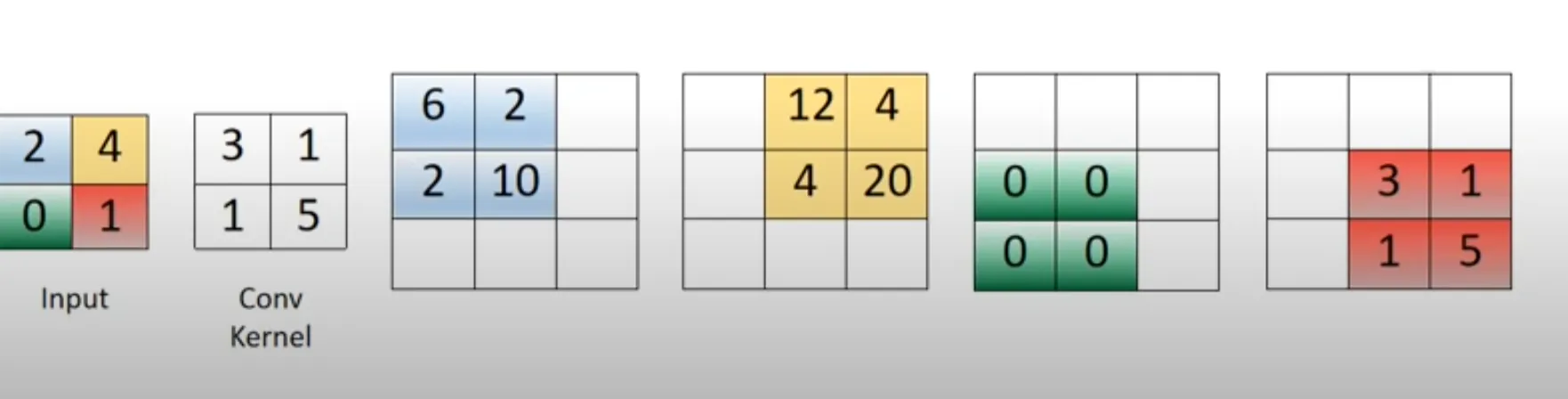
问题在于,我似乎找不到使用相同可视化方式来处理步幅和/或填充的示例。按照我的代码片段,我非常难以理解如何将填充应用于样本图像,或者步幅如何起作用以获得此输出。任何见解都将受到赞赏,即使只了解如何计算结果矩阵中(0,0)条目中的6或(0,1)条目中的12也将非常有帮助。




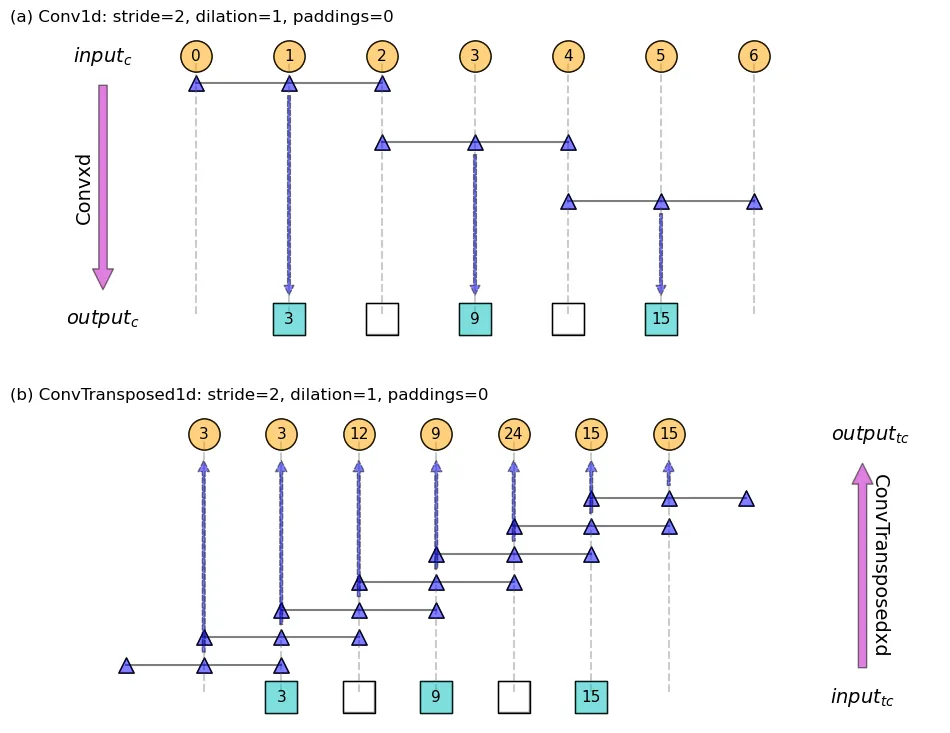
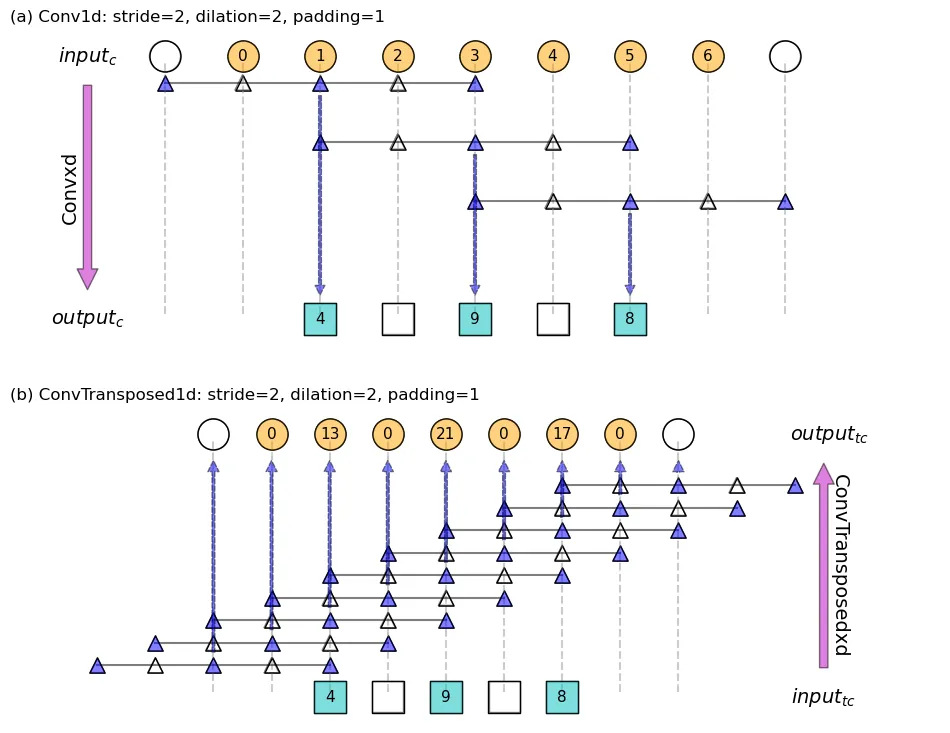
s=2,p=1吗? - Gilad