我处理图像处理。
我需要将16位整数SSE向量除以255。
由于255不是2的幂的倍数,因此我无法使用移位运算符如_mm_srli_epi16()。
当然,我知道可以将整数转换为浮点数,进行除法操作,然后再将其转换回整数。
但也许有人知道另一种解决方案...
我处理图像处理。
我需要将16位整数SSE向量除以255。
由于255不是2的幂的倍数,因此我无法使用移位运算符如_mm_srli_epi16()。
当然,我知道可以将整数转换为浮点数,进行除法操作,然后再将其转换回整数。
但也许有人知道另一种解决方案...
有一种整数近似除以255的方法:
inline int DivideBy255(int value)
{
return (value + 1 + (value >> 8)) >> 8;
}
使用SSE2,它将会是这样的:
inline __m128i DivideI16By255(__m128i value)
{
return _mm_srli_epi16(_mm_add_epi16(
_mm_add_epi16(value, _mm_set1_epi16(1)), _mm_srli_epi16(value, 8)), 8);
}
对于AVX2:
inline __m256i DivideI16By255(__m256i value)
{
return _mm256_srli_epi16(_mm256_add_epi16(
_mm256_add_epi16(value, _mm256_set1_epi16(1)), _mm256_srli_epi16(value, 8)), 8);
}
对于Altivec(Power):
typedef __vector int16_t v128_s16;
const v128_s16 K16_0001 = {1, 1, 1, 1, 1, 1, 1, 1};
const v128_s16 K16_0008 = {8, 8, 8, 8, 8, 8, 8, 8};
inline v128_s16 DivideBy255(v128_s16 value)
{
return vec_sr(vec_add(vec_add(value, K16_0001), vec_sr(value, K16_0008)), K16_0008);
}
对于 NEON(ARM):
inline int16x8_t DivideI16By255(int16x8_t value)
{
return vshrq_n_s16(vaddq_s16(
vaddq_s16(value, vdupq_n_s16(1)), vshrq_n_s16(value, 8)), 8);
}
value == 65535 和所有负数都是错误的(因此既不适用于有符号 16 位整数也不适用于无符号 16 位整数)。 - Anton Savinpmulhuw更有效,尽管延迟较差。我几年前的答案只考虑了有符号数,而没有考虑无符号数。(由于某种原因,似乎没有人区分这两者,有时使用int,有时使用SIMD逻辑右移。) - Peter Cordestypedef unsigned short vec_u16 __attribute__((vector_size(16)));
vec_u16 divu255(vec_u16 x){ return x/255; } // unsigned division
#gcc5.5 -O3 -march=haswell
divu255:
vpmulhuw xmm0, xmm0, XMMWORD PTR .LC3[rip] # _mm_set1_epi16(0x8081)
vpsrlw xmm0, xmm0, 7
ret
指令集版本:
// UNSIGNED division with intrinsics
__m128i div255_epu16(__m128i x) {
__m128i mulhi = _mm_mulhi_epu16(x, _mm_set1_epi16(0x8081));
return _mm_srli_epi16(mulhi, 7);
}
typedef short vec_s16 __attribute__((vector_size(16)));
vec_s16 div255(vec_s16 x){ return x/255; } // signed division
; function arg x starts in xmm0
vpmulhw xmm1, xmm0, XMMWORD PTR .LC3[rip] ; a vector of set1(0x8081)
vpaddw xmm1, xmm1, xmm0
vpsraw xmm0, xmm0, 15 ; 0 or -1 according to the sign bit of x
vpsraw xmm1, xmm1, 7 ; shift the mulhi-and-add result
vpsubw xmm0, xmm1, xmm0 ; result += (x<0)
.LC3:
.value -32639
.value -32639
; repeated
冒着答案膨胀的风险,这里再次使用内置函数进行翻译:
// SIGNED division
__m128i div255_epi16(__m128i x) {
__m128i tmp = _mm_mulhi_epi16(x, _mm_set1_epi16(0x8081));
tmp = _mm_add_epi16(tmp, x); // There's no integer FMA that's usable here
x = _mm_srai_epi16(x, 15); // broadcast the sign bit
tmp = _mm_srai_epi16(tmp, 7);
return _mm_sub_epi16(tmp, x);
}
set1和生成的div255常量。据我所知,这类似于字符串常量合并。GCC会优化x/255,其中x是unsigned short类型,优化结果为DWORD(x * 0x8081) >> 0x17,可以进一步简化为HWORD(x * 0x8081) >> 7,最终简化为HWORD((x << 15) + (x << 7) + x) >> 7。
SIMD宏可能如下所示:
#define MMX_DIV255_U16(x) _mm_srli_pi16(_mm_mulhi_pu16(x, _mm_set1_pi16((short)0x8081)), 7)
#define SSE2_DIV255_U16(x) _mm_srli_epi16(_mm_mulhi_epu16(x, _mm_set1_epi16((short)0x8081)), 7)
#define AVX2_DIV255_U16(x) _mm256_srli_epi16(_mm256_mulhi_epu16(x, _mm256_set1_epi16((short)0x8081)), 7)
准确版本:
#define div_255_fast(x) (((x) + (((x) + 257) >> 8)) >> 8)
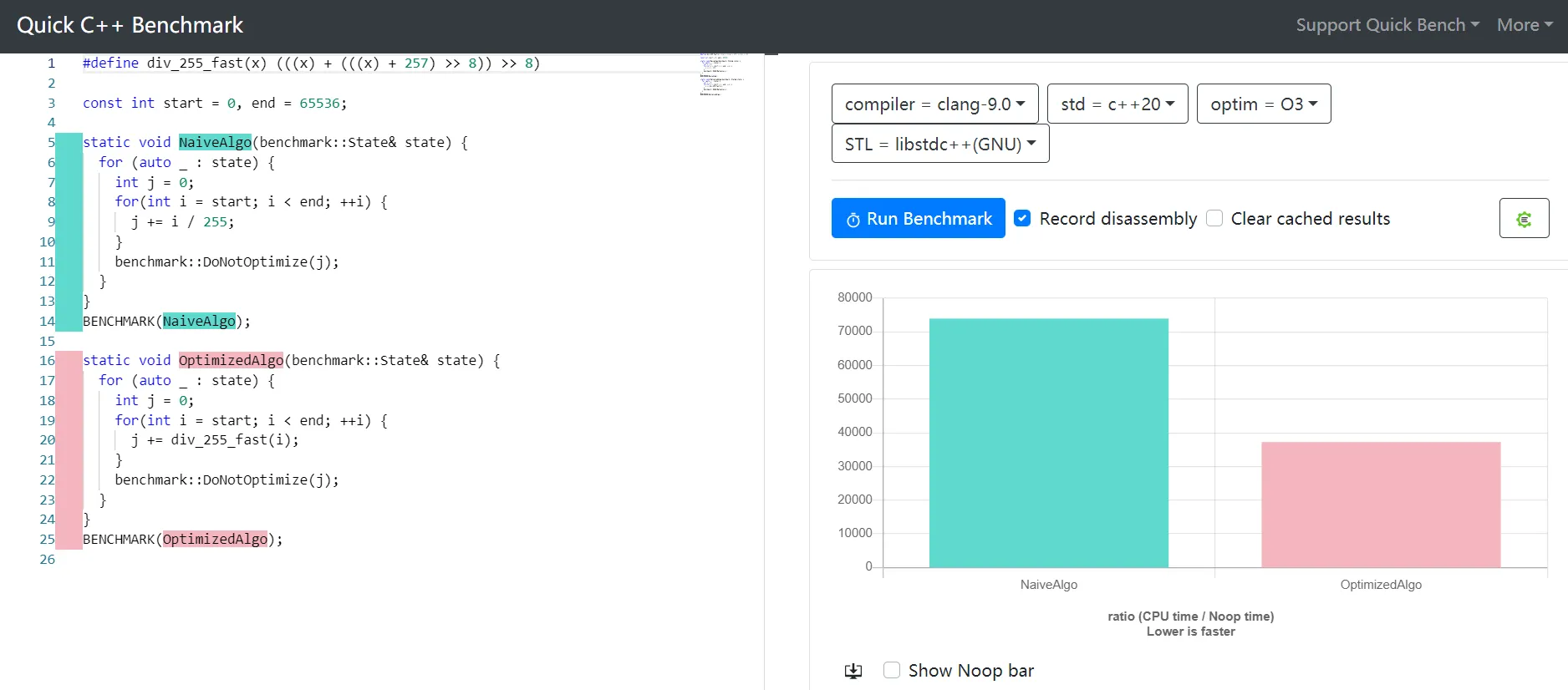
http://quick-bench.com/t3Y2-b4isYIwnKwMaPQi3n9dmtQ
SIMD版本:
// (x + ((x + 257) >> 8)) >> 8
static inline __m128i _mm_fast_div_255_epu16(__m128i x) {
return _mm_srli_epi16(_mm_adds_epu16(x,
_mm_srli_epi16(_mm_adds_epu16(x, _mm_set1_epi16(0x0101)), 8)), 8);
}
对于大于65535的正整数x,这里有另一种版本:
static inline int32_t fast_div_255_any (int32_t n) {
uint64_t M = (((uint64_t)1) << 40) / 255 + 1; // "1/255" in 24.40 fixed point number
return (M * n) >> 40; // fixed point multiply: n * (1/255)
}
更加广泛(需要64位乘法),但仍比div指令快。
[0, 65535] 或者 [0, 65536),因为 65536 = 2^16 超出了 epu16 的范围。 - Peter Cordesimul运算较慢。而且,如果你做了什么像使用int32_t x这样的傻事来进行x/255的有符号除法并迫使编译器处理它,那也会更慢。 - Peter Cordes出于好奇(并且如果性能是一个问题),以下是使用 (val + offset) >> 8 作为 (val / 255) 替代品的准确度,适用于所有16位值达到255*255(例如使用8位混合因子混合两个8位值时):
(avrg signed error / avrg abs error / max abs error)
offset 0: 0.49805 / 0.49805 / 1 (just shifting, no offset)
offset 0x7F: 0.00197 / 0.24806 / 1
offest 0x80: -0.00194 / 0.24806 / 1
所有其他的偏移量会产生更大的有符号和平均误差。因此,如果您可以接受小于0.25的平均误差,则可以使用偏移+移位来实现速度的小幅增加。
// approximate division by 255 for packs of 8 times 16bit values in vals_packed
__m128i offset = _mm_set1_epi16(0x80); // constant
__m128i vals_packed_offest = _mm_add_epi16( vals_packed, offset );
__m128i result_packed = _mm_srli_epi16( vals_packed_offest , 8 );
_mm_adds_epi16 或 epu16 用于有符号/无符号饱和。 您确定要使用 srli(逻辑右移)而不是算术右移 srai 吗? 还是您正在为无符号执行此操作? - Peter Cordes
srli而不是srai。 - Peter Cordes