我有一个CSV文件,想要了解它的编码方式。在Microsoft Excel中是否有菜单选项可以帮助我检测它的编码方式?
或者我需要使用类似C#或PHP的编程语言来推断它的编码方式。
你可以使用Notepad++来评估文件的编码,无需编写代码。打开文件的评估编码将显示在底部栏的最右侧。支持的编码可以通过转到设置 -> 首选项 -> 新文档/默认目录并查看下拉菜单来查看。
file blah.csv
输出:
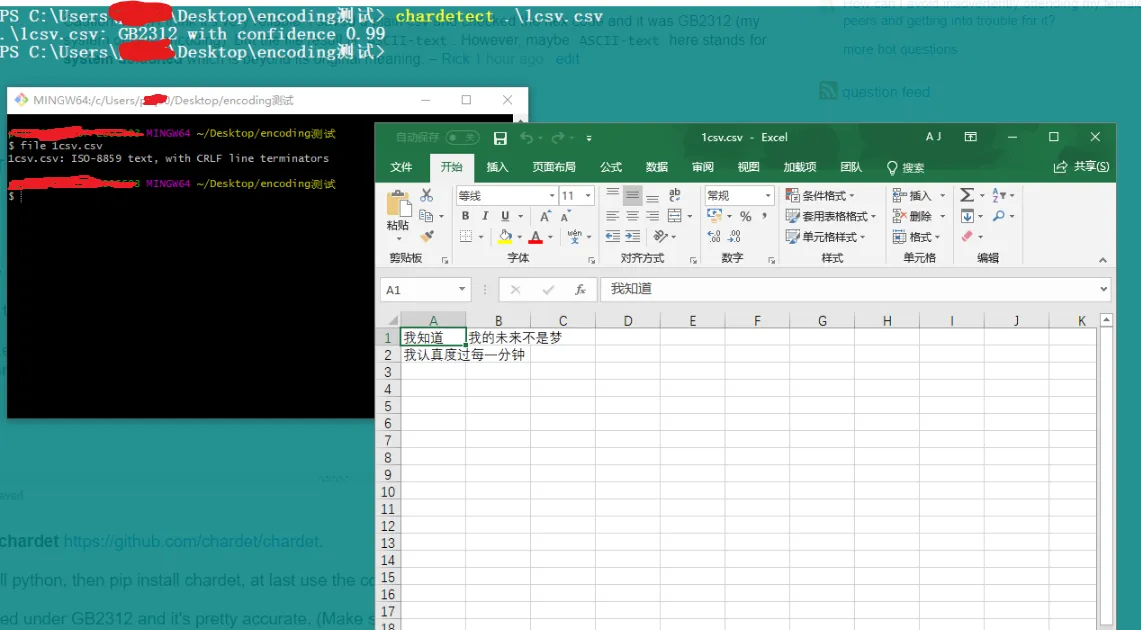
blah.csv: ISO-8859 text, with very long lines
with open('file_name.csv') as f:
print(f)
输出结果大致如下:
<_io.TextIOWrapper name='file_name.csv' mode='r' encoding='utf8'>
utf-16打开,但是本答案中的方法返回cp1252。尝试使用Pandas CSV读取器以cp1252打开它会返回ParserError,因此某些地方可能出了问题。 - Mastcp1252,即使我可以在Notepad++中看到csv文件是utf-8格式。只有当使用 with open('file_name.csv', encoding='utf-8') as f: 时,它才会实际显示utf-8,这并不是很有帮助。 - Benjicp1252。有关更多详细信息,请参见“open”文档。 - wjandrea你也可以使用Python的chardet库。
# install the chardet library
!pip install chardet
# import the chardet library
import chardet
# use the detect method to find the encoding
# 'rb' means read in the file as binary
with open("test.csv", 'rb') as file:
print(chardet.detect(file.read()))
使用 chardet https://github.com/chardet/chardet。(文档简短易懂)。
安装Python,然后通过pip安装chardet,在最后使用命令行命令。
我在GB2312下测试过,它非常准确。(请确保至少有几个字符,只有一个字符的样本很容易出错)。
file 不是可靠的工具,如下图所示:
或者您可以在Python控制台或Jupyter Notebook中执行:
import csv
data = open("file.csv","r")
data
您将看到有关数据对象的信息,如下所示:
<_io.TextIOWrapper name='arch.csv' mode='r' encoding='cp1250'>
如您所见,它包含编码信息。
CSV文件没有标头指示编码。
您只能通过以下方式猜测:
在2021年,表情符号被广泛使用,但许多导入工具无法导入它们。上面的答案中经常推荐使用chardet库,但该库不能很好地处理表情符号。
icecream = ''
import csv
with open('test.csv', 'w') as f:
wf = csv.writer(f)
wf.writerow(['ice cream', icecream])
import chardet
with open('test.csv', 'rb') as f:
print(chardet.detect(f.read()))
{'encoding': 'Windows-1254', 'confidence': 0.3864823918622268, 'language': 'Turkish'}
with open('test.csv', 'r', encoding='utf-8') as f:
print(f.read())
ice cream,
file 命令也检测到了这个。file test.csv
test.csv: UTF-8 Unicode text, with CRLF line terminators
如果自动检测出现问题,在尝试使用 chardet 之前,请先尝试使用 UTF-8。
from encodings.aliases import aliases
alias_values = set(aliases.values())
for encoding in set(aliases.values()):
try:
df=pd.read_csv("test.csv", encoding=encoding)
print('successful', encoding)
except:
pass
正如@3724913(Jitender Kumar)提到的那样,可以使用file命令(在Windows上的WSL中也适用),通过执行file --exclude encoding blah.csv命令并使用man file中提供的信息,我能够获得csv文件的编码信息,因为在我的系统上file blah.csv不会显示编码信息。
import pandas as pd
import chardet
def read_csv(path: str, size: float = 0.10) -> pd.DataFrame:
"""
Reads a CSV file located at path and returns it as a Pandas DataFrame. If
nrows is provided, only the first nrows rows of the CSV file will be
read. Otherwise, all rows will be read.
Args:
path (str): The path to the CSV file.
size (float): The fraction of the file to be used for detecting the
encoding. Defaults to 0.10.
Returns:
pd.DataFrame: The CSV file as a Pandas DataFrame.
Raises:
UnicodeError: If the encoding of the file cannot be detected with the
initial size, the function will retry with a larger size (increased by
0.20) until the encoding can be detected or an error is raised.
"""
try:
byte_size = int(os.path.getsize(path) * size)
with open(path, "rb") as rawdata:
result = chardet.detect(rawdata.read(byte_size))
return pd.read_csv(path, encoding=result["encoding"])
except UnicodeError:
return read_csv(path=path, size=size + 0.20)