我将使用Spark 2.1。
输入的csv文件包含Unicode字符,如下所示。
使用的Java代码为:

解析此csv文件时,输出结果如下所示
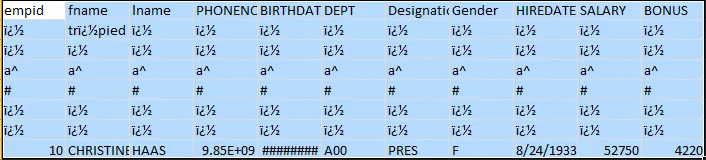
使用的Java代码为:
@Test
public void TestCSV() throws IOException {
String inputPath = "/user/jpattnaik/1945/unicode.csv";
String outputPath = "file:\\C:\\Users\\jpattnaik\\ubuntu-bkp\\backup\\bug-fixing\\1945\\output-csv";
getSparkSession()
.read()
.option("inferSchema", "true")
.option("header", "true")
.option("encoding", "UTF-8")
.csv(inputPath)
.write()
.option("header", "true")
.option("encoding", "UTF-8")
.mode(SaveMode.Overwrite)
.csv(outputPath);
}
如何获得与输入相同的输出?