@DasalKalubowila,这里是对@KresimirL答案的修改,可能是您正在寻找的。
首先,为您的输入数据创建一个定义名称。方法是在功能区中选择公式,然后在定义名称组下单击名称管理器。
在我的示例中,我将输入数据范围称为InputData。我使用的公式是
=Sheet1!$A$2:INDEX(Sheet1!$A$2:$A$501,MATCH("Ω",Sheet1!$A$2:$A$501))
其中
Sheet1 是输入数据所在的工作表名称,
$A$2 是输入范围中包含数据的第一个单元格(我称之为锚点),
$A$2:$A$501 是您的数据可能存在的列的最大区域,
"Ω" 是希腊字母Omega。您可以通过按住ALT键并在10键数字键盘上依次按下2、3、4来获取它(也可以在Windows的字符映射应用程序中找到它)。
这个公式根据存在的条目数量有效地扩展或缩小了您的数据范围。
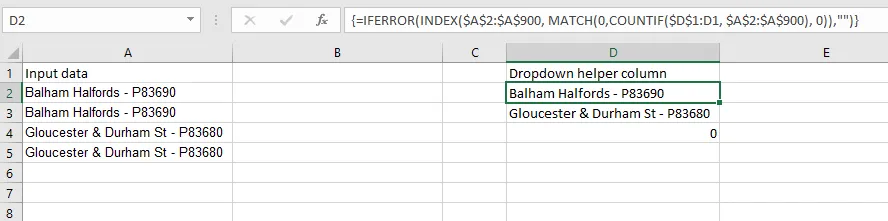
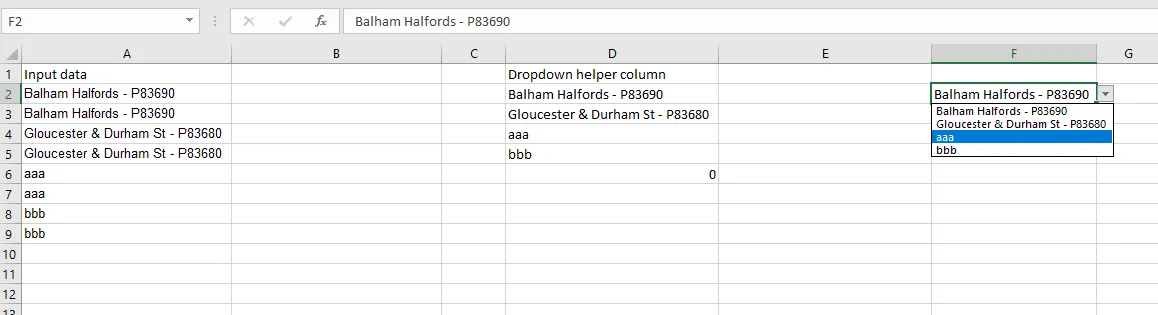
接下来,您需要创建一个辅助列。我知道这不是您想要的,但这将是其中唯一/更好的方法之一。我把我的放在与我的输入数据相同的工作表上,但您不必这样做。我在E2中使用的公式是
=IFERROR(INDEX(InputData,MATCH(0,COUNTIF($E$1:$E1,InputData),0)),"")
你需要使用 Ctrl+Shift+Enter 来提交这个数组公式。然后将该公式向下拖动到你需要的行数。你基本上需要向下拖动与你认为会有唯一条目相同的行数。
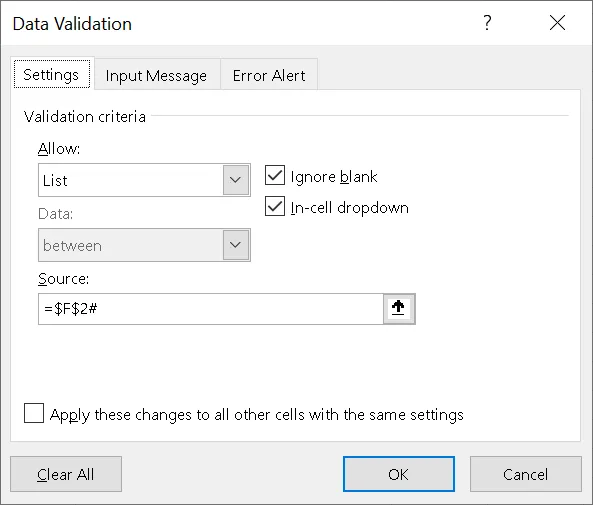
然后我需要创建一个更多的定义名称,这将在下一步中在我的数据验证下使用。我称这个新定义的名称为ValidationList(这需要作用于工作簿)。我用于ValidationList的公式是
=Sheet1!$E$2:INDEX(Sheet1!$E$2:$E$501,COUNTIF(Sheet1!$E$2:$E$501,">*"))
查看上面有关InputData的注释以更好地理解这个公式。唯一的区别是,该公式使用COUNTIF而不是MATCH。这是因为如果你的唯一值尚未填充你拖动到E列 (在之前的步骤中),则与以前相同的方式使用MATCH会抓取我们不需要的许多空白。因此,COUNTIF仅计算那些包含大于“*”的值的单元格(星号是任意字符的通配符,“”不包含任何字符,因此它排除了这些项目)。
现在,创建您的数据验证并将其设置如下:
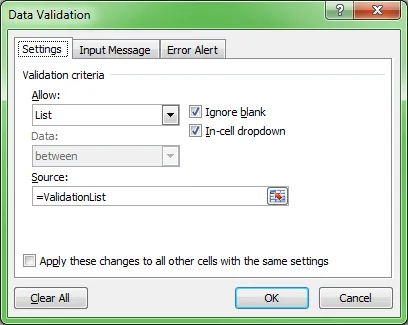
现在,你应该只剩下这个了:

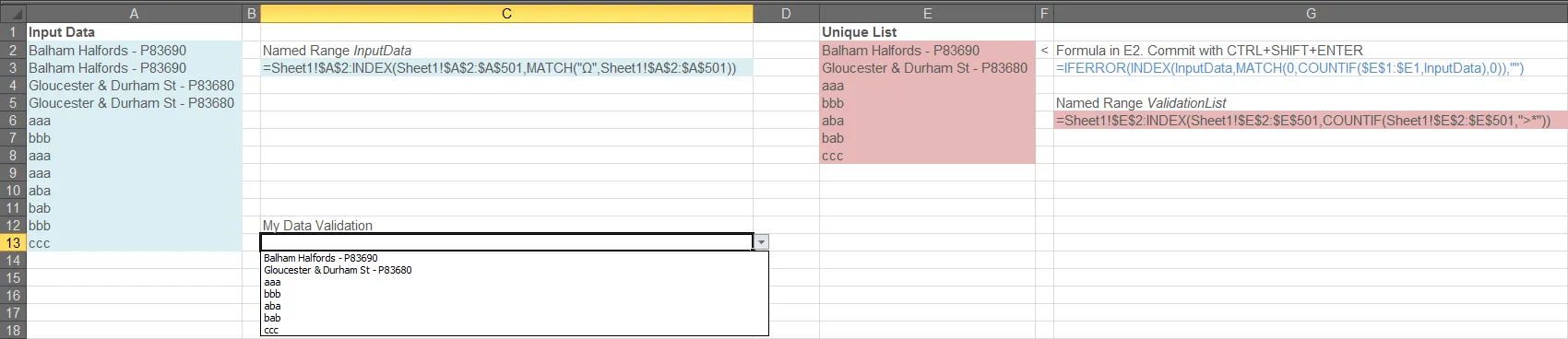
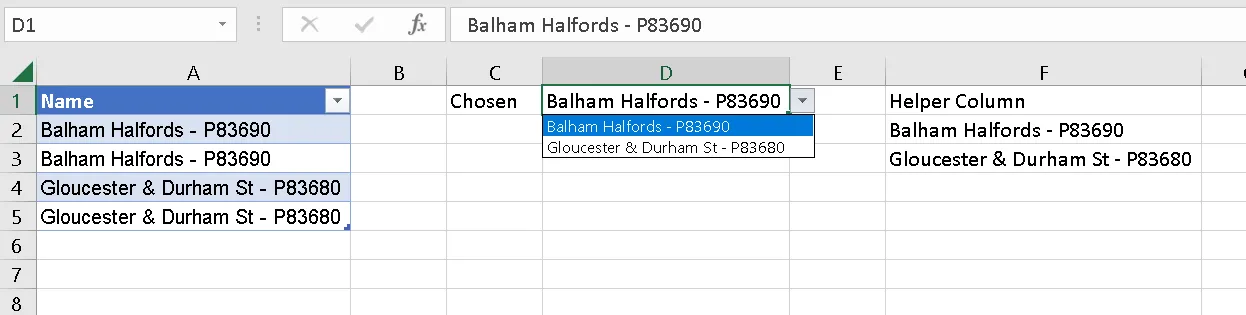
当您向
InputData区域添加信息时,您的
ValidationList范围应扩展以包括最新的唯一值,这将反过来填充到
Data Validation区域中,如下所示:
我发现这似乎不会显著减慢我的工作簿速度,但我很想听听它在您的电脑上的表现如何。
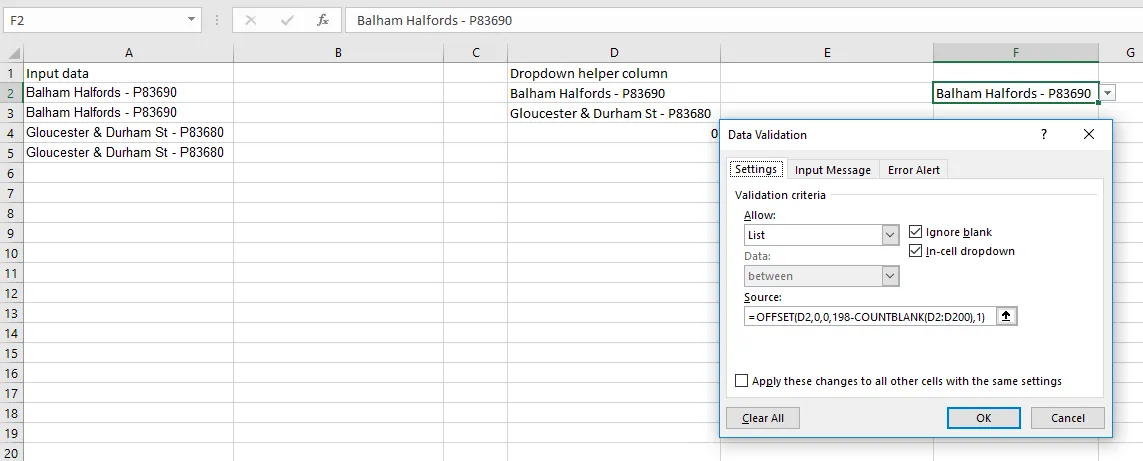
OFFSET,这可能会对你有所帮助。 - TotsieMae