以下是一个dataframe示例:
from pyspark.sql.functions import avg, first
rdd = sc.parallelize(
[
(0, "A", 223,"201603", "PORT"),
(0, "A", 22,"201602", "PORT"),
(0, "A", 422,"201601", "DOCK"),
(1,"B", 3213,"201602", "DOCK"),
(1,"B", 3213,"201601", "PORT"),
(2,"C", 2321,"201601", "DOCK")
]
)
df_data = sqlContext.createDataFrame(rdd, ["id","type", "cost", "date", "ship"])
df_data.show()
我对它进行了数据透视表操作,
df_data.groupby(df_data.id, df_data.type).pivot("date").agg(avg("cost"), first("ship")).show()
+---+----+----------------+--------------------+----------------+--------------------+----------------+--------------------+
| id|type|201601_avg(cost)|201601_first(ship)()|201602_avg(cost)|201602_first(ship)()|201603_avg(cost)|201603_first(ship)()|
+---+----+----------------+--------------------+----------------+--------------------+----------------+--------------------+
| 2| C| 2321.0| DOCK| null| null| null| null|
| 0| A| 422.0| DOCK| 22.0| PORT| 223.0| PORT|
| 1| B| 3213.0| PORT| 3213.0| DOCK| null| null|
+---+----+----------------+--------------------+----------------+--------------------+----------------+--------------------+
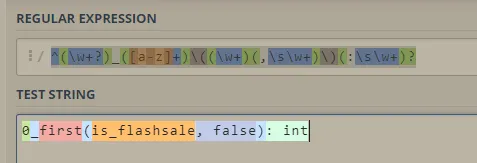
但是我得到的这些列名非常复杂。在聚合操作中应用别名(alias)通常有效,但由于此处使用了透视(pivot),因此列名变得更加糟糕:
+---+----+--------------------------------------------------------------+------------------------------------------------------------------+--------------------------------------------------------------+------------------------------------------------------------------+--------------------------------------------------------------+------------------------------------------------------------------+
| id|type|201601_(avg(cost),mode=Complete,isDistinct=false) AS cost#1619|201601_(first(ship)(),mode=Complete,isDistinct=false) AS ship#1620|201602_(avg(cost),mode=Complete,isDistinct=false) AS cost#1619|201602_(first(ship)(),mode=Complete,isDistinct=false) AS ship#1620|201603_(avg(cost),mode=Complete,isDistinct=false) AS cost#1619|201603_(first(ship)(),mode=Complete,isDistinct=false) AS ship#1620|
+---+----+--------------------------------------------------------------+------------------------------------------------------------------+--------------------------------------------------------------+------------------------------------------------------------------+--------------------------------------------------------------+------------------------------------------------------------------+
| 2| C| 2321.0| DOCK| null| null| null| null|
| 0| A| 422.0| DOCK| 22.0| PORT| 223.0| PORT|
| 1| B| 3213.0| PORT| 3213.0| DOCK| null| null|
+---+----+--------------------------------------------------------------+------------------------------------------------------------------+--------------------------------------------------------------+------------------------------------------------------------------+--------------------------------------------------------------+------------------------------------------------------------------+
有没有一种方法可以在透视和聚合时即时更改列名?