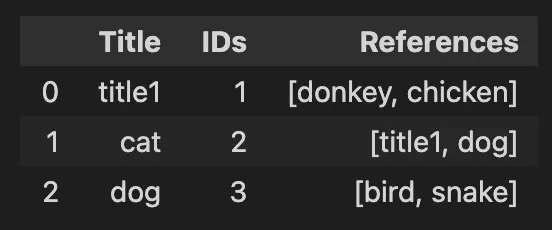
我有一个像这样的数据框
#Test dataframe
import pandas as pd
import numpy as np
#Build df
titles = {'Title': ['title1', 'cat', 'dog']}
references = {'References': [['donkey','chicken'],['title1','dog'],['bird','snake']]}
df = pd.DataFrame({'Title': ['title1', 'cat', 'dog'], 'References': [['donkey','chicken'],['title1','dog'],['bird','snake']]})
#Insert IDs for UNIQUE titles
title_ids = {'IDs':list(np.arange(0,len(df)) + 1)}
df['IDs'] = list(np.arange(0,len(df)) + 1)
df = df[['Title','IDs','References']]

我的第一次尝试是使用函数
#Matching function
def string_match(string1,string2):
if string1 == string2:
a = 1
else:
a = 0
return a
我希望能够循环遍历每个字符串/标题组合,但是如果使用多个for循环和if语句会变得很棘手。有没有更符合Python风格的方法可以解决这个问题?