如何将DataFrame中的字符串列(格式为dd/mm/yyyy)转换为datetime数据类型?
7个回答
720
最简单的方法是使用to_datetime函数:
df['col'] = pd.to_datetime(df['col'])
它还提供了一个dayfirst参数用于欧洲时间(但要注意这不是严格的)。
下面是示例:
In [11]: pd.to_datetime(pd.Series(['05/23/2005']))
Out[11]:
0 2005-05-23 00:00:00
dtype: datetime64[ns]
In [12]: pd.to_datetime(pd.Series(['05/23/2005']), format="%m/%d/%Y")
Out[12]:
0 2005-05-23
dtype: datetime64[ns]
- Andy Hayden
1
72
如果你的日期列是一个格式为'2017-01-01'的字符串,你可以使用pandas的astype将其转换为日期时间格式。
如果你想要天的精确度而不是纳秒,可以使用datetime64[D]。
产量
和使用pandas.to_datetime一样
你可以尝试其他格式,不过至少这个格式是有效的。
df['date'] = df['date'].astype('datetime64[ns]')
如果你想要天的精确度而不是纳秒,可以使用datetime64[D]。
print(type(df['date'].iloc[0]))
产量
<class 'pandas._libs.tslib.Timestamp'>
和使用pandas.to_datetime一样
你可以尝试其他格式,不过至少这个格式是有效的。
- sigurdb
1
请注意,当字符串中指定了时区时,它会忽略它。 - fantabolous
55
如果您想指定复杂的格式,可以使用以下内容:
df['date_col'] = pd.to_datetime(df['date_col'], format='%d/%m/%Y')
更多关于格式化的细节请参考:
- Ekhtiar
23
如果您的日期格式混合在一起,请不要忘记设置
infer_datetime_format=True,以便更轻松地处理。df['date'] = pd.to_datetime(df['date'], infer_datetime_format=True)
或者如果你想要一种定制化的方法:
def autoconvert_datetime(value):
formats = ['%m/%d/%Y', '%m-%d-%y'] # formats to try
result_format = '%d-%m-%Y' # output format
for dt_format in formats:
try:
dt_obj = datetime.strptime(value, dt_format)
return dt_obj.strftime(result_format)
except Exception as e: # throws exception when format doesn't match
pass
return value # let it be if it doesn't match
df['date'] = df['date'].apply(autoconvert_datetime)
- otaku
2
可以使用定制化的方法,而不必使用没有快速缓存且在转换十亿个值时会遇到困难的
.apply。另一种选择是col = pd.concat([pd.to_datetime(col, errors='coerce', format=f) for f in formats], axis='columns').bfill(axis='columns').iloc[:, 0],但并不是一个很好的选择。 - Asclepius3如果您的数据格式混杂不一,**不应使用
infer_datetime_format=True**,因为它假设只有一个日期时间格式。请跳过此参数。要了解原因,请尝试使用pd.to_datetime(pd.Series(['1/5/2015 8:08:00 AM', '1/4/2015 11:24:00 PM']), infer_datetime_format=True)与和没有errors='coerce'。请参阅此问题。 - Asclepius8
多个日期时间列
如果您想将多个字符串列转换为日期时间格式,则可以使用 apply() 方法。
df[['date1', 'date2']] = df[['date1', 'date2']].apply(pd.to_datetime)
您可以将参数作为 kwargs 传递给 to_datetime。
df[['start_date', 'end_date']] = df[['start_date', 'end_date']].apply(pd.to_datetime, format="%m/%d/%Y")
在不指定
axis的情况下传递给apply,仍然会将值向量化地转换对于每一列。这里需要使用apply,因为pd.to_datetime只能在单个列上调用。如果必须在多个列上调用它,则选项是使用显式的for-loop或将其传递给apply。另一方面,如果您使用apply在一列上调用pd.to_datetime(例如df['date'].apply(pd.to_datetime)),那么这将不是矢量化的,并且应该避免使用。
使用format=加速
如果列包含时间组件,并且您知道日期时间/时间的格式,则显式传递格式将显着加快转换速度。但是,如果该列仅包含日期,则几乎没有任何区别。在我的项目中,对于包含500万行的列,差异非常大:约2.5分钟与6秒。
事实证明,显式指定格式大约快25倍。以下运行时图表显示,根据是否传递格式,性能差距巨大。
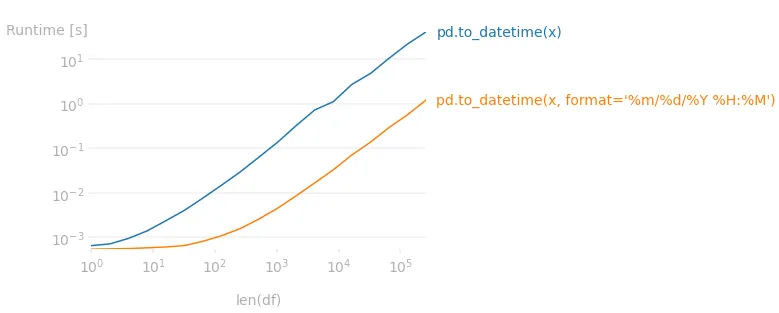
生成图表所使用的代码:
import perfplot
import random
mdYHM = range(1, 13), range(1, 29), range(2000, 2024), range(24), range(60)
perfplot.show(
kernels=[lambda x: pd.to_datetime(x), lambda x: pd.to_datetime(x, format='%m/%d/%Y %H:%M')],
labels=['pd.to_datetime(x)', "pd.to_datetime(x, format='%m/%d/%Y %H:%M')"],
n_range=[2**k for k in range(19)],
setup=lambda n: pd.Series([f"{m}/{d}/{Y} {H}:{M}"
for m,d,Y,H,M in zip(*[random.choices(e, k=n) for e in mdYHM])]),
equality_check=pd.Series.equals,
xlabel='len(df)'
)
- cottontail
0
尝试以下解决方案:
- 将
'2022–12–31 00:00:00'更改为'2022–12–31 00:00:01' - 然后运行此代码:
pandas.to_datetime(pandas.Series(['2022–12–31 00:00:01'])) - 输出:
2022–12–31 00:00:01
- Scarlett
1
将“2022–12–31 00:00:00”更改为“2022–12–31 00:00:01” - 这与问题有什么关系? - undefined
-1
print(df1.shape)
(638765, 95)
%timeit df1['Datetime'] = pd.to_datetime(df1['Date']+" "+df1['HOUR'])
473 ms ± 8.33 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df1['Datetime'] = pd.to_datetime(df1['Date']+" "+df1['HOUR'], format='mixed')
688 ms ± 3.14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit df1['Datetime'] = pd.to_datetime(df1['Date']+" "+df1['HOUR'], format='%Y-%m-%d %H:%M:%S')
470 ms ± 7.31 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
- Mainland
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
dd/mm/yyyy和一些dd/mm/yyyy hh:mm:ss),则请参阅此帖子及其答案,以了解一种有效解析它的方法。 - cottontail