我正在使用状态转换器来在2D递归行走的每个点上随机采样数据集,该状态转换器输出一系列满足条件的2D样本网格列表。我想懒惰地从结果中获取数据,但我的方法会在我提取第一个结果之前在每个点耗尽整个数据集。
具体来说,考虑下面这个程序:
该程序沿着从
在所提供的代码中,它会抛出
如果我们
具体来说,考虑下面这个程序:
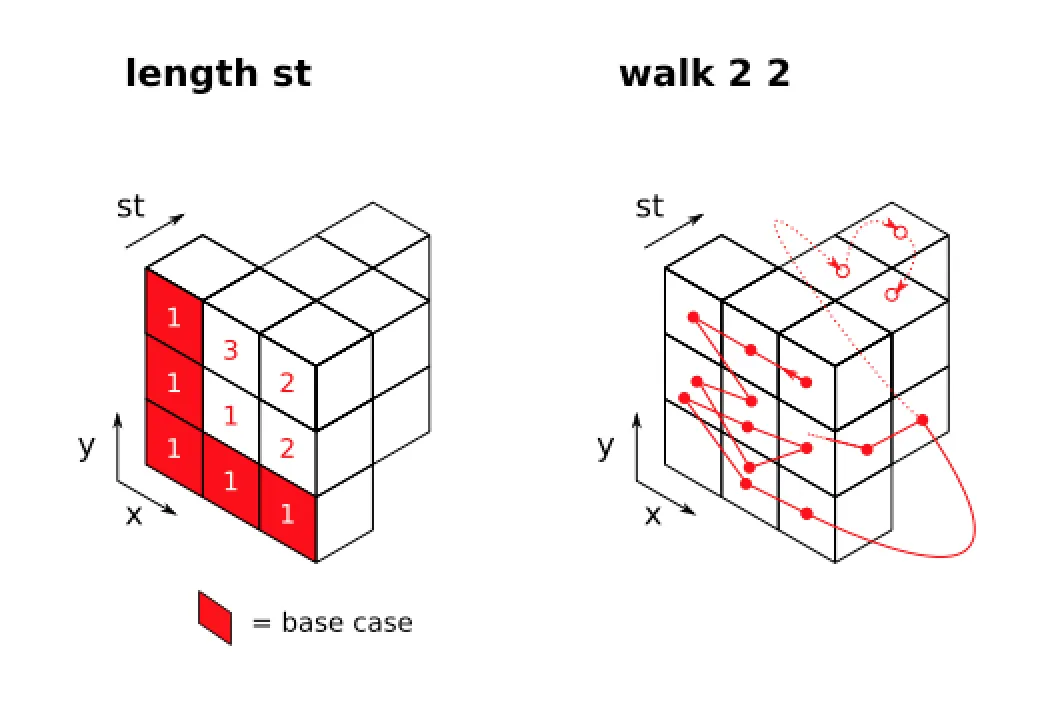
import Control.Monad ( sequence, liftM2 )
import Data.Functor.Identity
import Control.Monad.State.Lazy ( StateT(..), State(..), runState )
walk :: Int -> Int -> [State Int [Int]]
walk _ 0 = [return [0]]
walk 0 _ = [return [0]]
walk x y =
let st :: [State Int Int]
st = [StateT (\s -> Identity (s, s + 1)), undefined]
unst :: [State Int Int] -- degenerate state tf
unst = [return 1, undefined]
in map (\m_z -> do
z <- m_z
fmap concat $ sequence [
liftM2 (zipWith (\x y -> x + y + z)) a b -- for 1D: map (+z) <$> a
| a <- walk x (y - 1) -- depth
, b <- walk (x - 1) y -- breadth -- comment out for 1D
]
) st -- vs. unst
main :: IO ()
main = do
std <- getStdGen
putStrLn $ show $ head $ fst $ (`runState` 0) $ head $ walk 2 2
该程序沿着从
(x, y)到(0, 0)的矩形网格行走并求和所有结果,包括其中一个State monads列表的值:要么是读取并推进其状态的非平凡变压器st,要么是平凡变压器unst。有趣的是算法是否探索了st和unst的头部之后。在所提供的代码中,它会抛出
undefined。我认为这是我的变换链接顺序设计不良的结果,特别是与状态处理有关,因为使用unst(即将结果与状态转换解耦)确实会产生结果。然而,我还发现1D递归即使使用状态变换也保留了惰性(删除广度步骤b < - walk...并将liftM2块替换为fmap)。如果我们
trace(show(x,y)),我们还可以看到它在触发前走完整个网格:$ cabal run
Build profile: -w ghc-8.6.5 -O1
...
(2,2)
(2,1)
(1,2)
(1,1)
(1,1)
sandbox: Prelude.undefined
我怀疑我的使用sequence是有问题的,但选择单子和漫步的维度会影响其成功性,所以我不能广泛地说sequence转换本身就是严格性的原因。
在这里导致1D和2D递归严格性差异的是什么,并且我该如何实现我想要的惰性?