我试图找到最快的矩阵乘法方法,并尝试了三种不同的方式:
- 纯Python实现:没有什么意外。
- Numpy实现,使用
numpy.dot(a, b) - 使用Python中的
ctypes模块与C进行交互。
以下是被转换为共享库的C代码:
#include <stdio.h>
#include <stdlib.h>
void matmult(float* a, float* b, float* c, int n) {
int i = 0;
int j = 0;
int k = 0;
/*float* c = malloc(nay * sizeof(float));*/
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
int sub = 0;
for (k = 0; k < n; k++) {
sub = sub + a[i * n + k] * b[k * n + j];
}
c[i * n + j] = sub;
}
}
return ;
}
接下来是调用它的 Python 代码:
def C_mat_mult(a, b):
libmatmult = ctypes.CDLL("./matmult.so")
dima = len(a) * len(a)
dimb = len(b) * len(b)
array_a = ctypes.c_float * dima
array_b = ctypes.c_float * dimb
array_c = ctypes.c_float * dima
suma = array_a()
sumb = array_b()
sumc = array_c()
inda = 0
for i in range(0, len(a)):
for j in range(0, len(a[i])):
suma[inda] = a[i][j]
inda = inda + 1
indb = 0
for i in range(0, len(b)):
for j in range(0, len(b[i])):
sumb[indb] = b[i][j]
indb = indb + 1
libmatmult.matmult(ctypes.byref(suma), ctypes.byref(sumb), ctypes.byref(sumc), 2);
res = numpy.zeros([len(a), len(a)])
indc = 0
for i in range(0, len(sumc)):
res[indc][i % len(a)] = sumc[i]
if i % len(a) == len(a) - 1:
indc = indc + 1
return res
我原本认为使用C的版本会更快...但结果证明我错了!以下是我的基准测试,显示我可能要么执行不正确,要么numpy真的异常快:
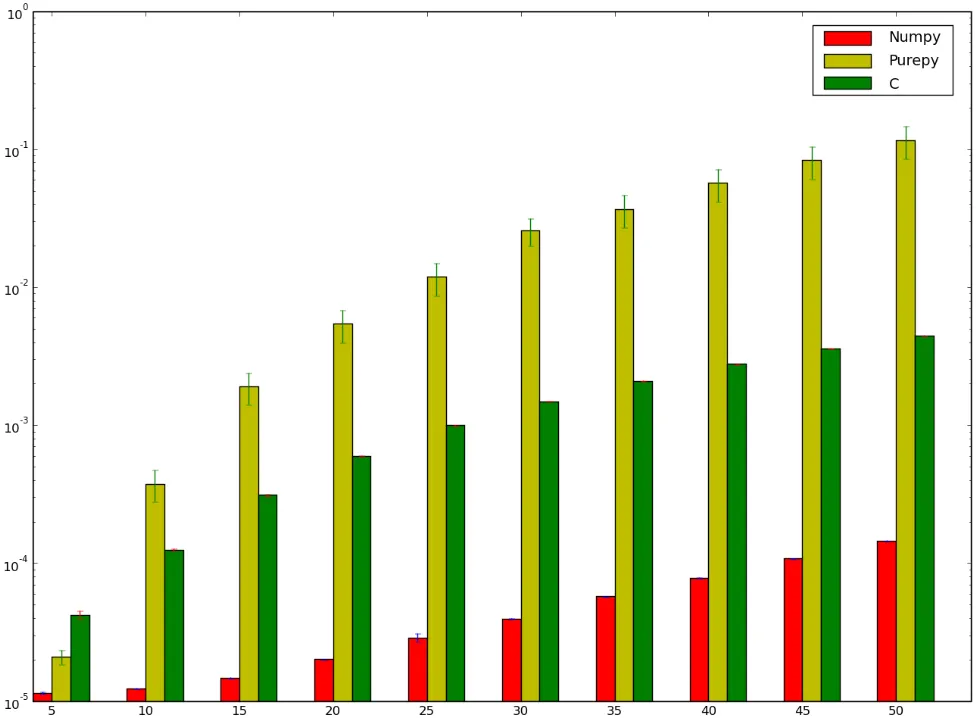
我想了解为什么numpy版本比ctypes版本更快,我甚至不是在讨论纯Python实现,因为那显然很慢。
k)中的b[k * n + j];具有步幅为n,因此它在每次访问时都会触及不同的缓存行,并且你的循环无法使用SSE/AVX进行自动向量化。通过提前转置b来解决这个问题,这会花费O(n^2)的时间,但在从b进行O(n^3)加载时,通过减少缓存未命中可以回报其本身的代价。尽管如此,这仍然是一个naive实现,没有使用缓存块(又称循环分块)。 - Peter Cordesint sum(出于某种原因...),如果内部循环正在访问两个连续的数组,则您的循环实际上可以进行矢量化而无需-ffast-math。FP数学不是结合律,因此编译器无法在没有-ffast-math的情况下重新排序操作,但整数数学是结合律的(并且比FP加法具有更低的延迟,这有助于如果您不打算使用多个累加器或其他延迟隐藏技术来优化循环)。float->int转换的成本与 FPadd相当(实际上在 Intel CPU 上使用 FP add ALU),因此在优化的代码中不值得。 - Peter Cordes