我一直在热衷地谷歌搜索,但找不到答案。
使用sklearn如何计算f统计量?根据公式,我真的必须手动计算吗?
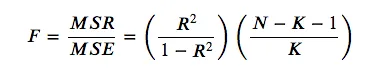
(其中 是观察次数, 是变量的数量)。
而且...如果我手动计算,如何获得相关的p值?
我一直在热衷地谷歌搜索,但找不到答案。
使用sklearn如何计算f统计量?根据公式,我真的必须手动计算吗?
(其中 是观察次数, 是变量的数量)。
而且...如果我手动计算,如何获得相关的p值?
我希望这可以帮到您!查找f-统计量的方法如下:
import sklearn
from sklearn.linear_model import LinearRegression
X, y = df[['x1','x2']], df[['y']]
model=LinearRegression().fit(X, y)
Rsq = model.score
fstat = (Rsq/(1-Rsq))*((N-K-1)/K) #you should find N and K yourself
import symbulate as sm
dfN = 5 -1 #degrees of freedom in the numerator of F-statistic
dfD = 2 -1 #degrees of freedom in the denominator of F-statistic
pVal = 1-sm.F(dfN,dfD).cdf(fstat)
p_val = 1 - sm.F(K - 1, N - K).cdf(fstat) - Ryan J McCall这是@jros的答案的实现。
import symbulate, sys
def f_test( r2, num_examples, num_features, alpha=0.05):
def _f_statistic(r2, num_examples, num_features):
if r2 <= 0 or r2 >= 1.0:
return float('nan')
n = num_examples # num observations
k = num_features # predictor variables
return (r2/(1-r2))*((n-k-1)/k)
def _f_pvalue(fstat, num_examples, num_features):
dfN = num_examples -1 #degrees of freedom in the numerator of F-statistic
dfD = num_features -1 #degrees of freedom in the denominator of F-statistic
if num_examples < 1 or num_features <1:
return float('nan')
if num_examples <= 1 or num_features <= 1:
dfN = num_examples
dfD = num_features
sys.stderr.write('Warning: F-Pvalue continuing with ddof=0, due to too few num_features or num_examples.'+\
'\nddof=1 provides an unbiased estimator of the variance of a hypothetical infinite population.'+\
'\nddof=0 provides a maximum likelihood estimate of the variance for normally distributed variables.')
sys.stdout.flush()
sys.stderr.flush()
return 1-symbulate.F(dfN,dfD).cdf(fstat)
f_stat = _f_statistic(r2, num_examples, num_features)
f_pvalue = _f_pvalue(f_stat, num_examples, num_features)
return f_stat, f_pvalue, f_pvalue < alpha
for k in range(2,4,1):
print(f'k={k}')
for i in range(1,21,1):
n = 100
print(' - r2=', i/20,f'\tn={n}, k={k}', f_test( r2=i/20, num_examples=n, num_features=k) )
输出:
k=2
- r2= 0.05 n=100, k=2 (2.5526315789473686, 0.467180032853742, False)
- r2= 0.1 n=100, k=2 (5.388888888888889, 0.33243150497952834, False)
- r2= 0.15 n=100, k=2 (8.558823529411764, 0.2667864560583846, False)
- r2= 0.2 n=100, k=2 (12.125, 0.2254277638297868, False)
- r2= 0.25 n=100, k=2 (16.166666666666664, 0.19589812764564452, False)
- r2= 0.3 n=100, k=2 (20.78571428571429, 0.1731630776385309, False)
- r2= 0.35 n=100, k=2 (26.115384615384613, 0.1547401669655668, False)
- r2= 0.4 n=100, k=2 (32.333333333333336, 0.13923929277425262, False)
- r2= 0.45 n=100, k=2 (39.68181818181818, 0.1258080308171604, False)
- r2= 0.5 n=100, k=2 (48.5, 0.11388517598661818, False)
- r2= 0.55 n=100, k=2 (59.27777777777779, 0.10307787986420647, False)
- r2= 0.6 n=100, k=2 (72.74999999999999, 0.09309424892249041, False)
- r2= 0.65 n=100, k=2 (90.07142857142858, 0.08370256307272628, False)
- r2= 0.7 n=100, k=2 (113.16666666666666, 0.07470306947285188, False)
- r2= 0.75 n=100, k=2 (145.5, 0.06590367373435868, False)
- r2= 0.8 n=100, k=2 (194.00000000000006, 0.05709075345477199, False)
- r2= 0.85 n=100, k=2 (274.8333333333333, 0.047978063365596846, True)
- r2= 0.9 n=100, k=2 (436.5000000000001, 0.03807884617117241, True)
- r2= 0.95 n=100, k=2 (921.4999999999991, 0.02621297849969806, True)
- r2= 1.0 n=100, k=2 (nan, nan, False)
k=3
- r2= 0.05 n=100, k=3 (1.6842105263157896, 0.4457931140711229, False)
- r2= 0.1 n=100, k=3 (3.555555555555556, 0.24455931254075325, False)
- r2= 0.15 n=100, k=3 (5.647058823529412, 0.16202527006143097, False)
- r2= 0.2 n=100, k=3 (8.0, 0.11736403752951685, False)
- r2= 0.25 n=100, k=3 (10.666666666666666, 0.08940890329736484, False)
- r2= 0.3 n=100, k=3 (13.714285714285715, 0.07027181885219369, False)
- r2= 0.35 n=100, k=3 (17.23076923076923, 0.056351674881635616, False)
- r2= 0.4 n=100, k=3 (21.333333333333336, 0.045772168919257394, True)
- r2= 0.45 n=100, k=3 (26.18181818181818, 0.03746005897185367, True)
- r2= 0.5 n=100, k=3 (32.0, 0.030757208722467566, True)
- r2= 0.55 n=100, k=3 (39.11111111111112, 0.025237649467887202, True)
- r2= 0.6 n=100, k=3 (47.99999999999999, 0.020613526135724203, True)
- r2= 0.65 n=100, k=3 (59.42857142857144, 0.01668332945750539, True)
- r2= 0.7 n=100, k=3 (74.66666666666666, 0.013301784491033142, True)
- r2= 0.75 n=100, k=3 (96.0, 0.010361516564533546, True)
- r2= 0.8 n=100, k=3 (128.00000000000003, 0.007781450084964225, True)
- r2= 0.85 n=100, k=3 (181.33333333333331, 0.005499222325884623, True)
- r2= 0.9 n=100, k=3 (288.00000000000006, 0.0034660796763316126, True)
- r2= 0.95 n=100, k=3 (607.9999999999994, 0.0016433577243727404, True)
- r2= 1.0 n=100, k=3 (nan, nan, False)