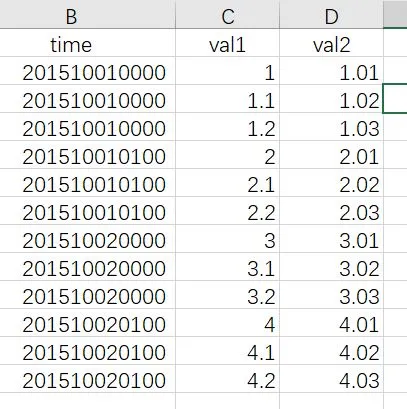
我有一个像这样的.txt文件:
# 经纬度
x1 = 11.21
x2 = 11.51
y1 = 27.84
y2 = 10.08
time: 201510010000
变量名: val1
[1.1,1.2,1.3]
变量名: va2
[1.0,1.01,1.02]
time: 201510010100
变量名: val1
[2.1,2.2,2.3]
变量名: va2
[2.01,2.02,2.03]
time: 2015020000
变量名: val1
[3.0,3.1,3.2]
变量名: val2
[3.01,3.02,3.03]
time: 2015020100
变量名: val1
[4.0,4.1,4.2]
变量名: val2
[401,4.02,4.03]
并且,我希望能够用Python读取它,像这样:
with open('text.txt','r',encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
print(line,)
这是我所做的,但我对下一步没有头绪。
我该如何达成它?
a.txt文件并打开了text.txt文件来读取?请问你是否能清楚地表达你的问题? - Ersel Er