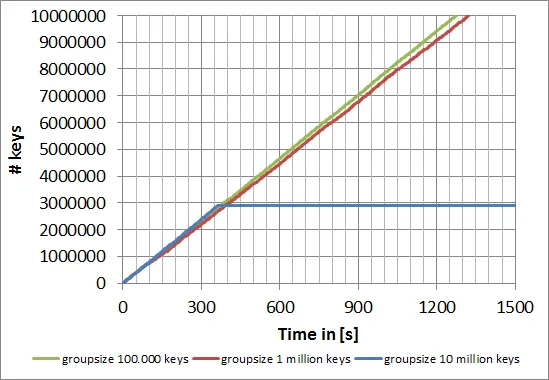
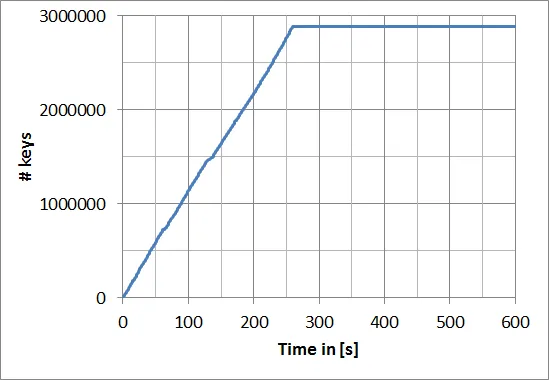
使用h5py创建一个包含多个数据集的hdf5文件时,我遇到了一个巨大的速度下降,大约在2.88百万个数据集后。这是什么原因?
我猜测数据集的树结构达到了极限,所以需要重新排序树结构,这非常耗时。
以下是一个简短的示例:
我猜测数据集的树结构达到了极限,所以需要重新排序树结构,这非常耗时。
以下是一个简短的示例:
import h5py
import time
hdf5_file = h5py.File("C://TEMP//test.hdf5")
barrier = 1
start = time.clock()
for i in range(int(1e8)):
hdf5_file.create_dataset(str(i), [])
td = time.clock() - start
if td > barrier:
print("{}: {}".format(int(td), i))
barrier = int(td) + 1
if td > 600: # cancel after 600s
break
编辑:
通过对数据集进行分组,可以避免这种限制:
import h5py
import time
max_n_keys = int(1e7)
max_n_group = int(1e5)
hdf5_file = h5py.File("C://TEMP//test.hdf5", "w")
group_key= str(max_n_group)
hdf5_file.create_group(group_key)
barrier=1
start = time.clock()
for i in range(max_n_keys):
if i>max_n_group:
max_n_group += int(1e5)
group_key= str(max_n_group)
hdf5_file.create_group(group_key)
hdf5_file[group_key].create_dataset(str(i), data=[])
td = time.clock() - start
if td > barrier:
print("{}: {}".format(int(td), i))
barrier = int(td) + 1