我正在尝试开发一种算法,可以将音乐文件中的器乐音符分离出来。使用了C#和C++ DLL。我已经花费了相当长的时间来实现它。目前为止,我所做的是:
- 在PCM上执行专门的FFT(它在时间和频率域中都具有高分辨率)
- 对FFT bin进行滤波器计算以模拟人类听觉系统(心理声学模型)
- 通过峰值检测进行模式识别,以为某些机器学习内容提供输入数据(当前规划阶段)
在当前进展中,我使用了简单的方法“选择本地最大值”来检测峰值。粗略地说,如果f(x-1)< f(x)> f(x+1),其中f(x)的频率响应且x是频率索引,则检测为峰值。
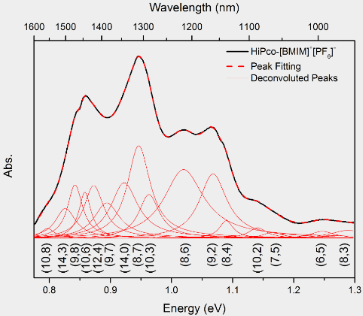
但是我在这里遇到了一些问题。如果两个或更多信号在频率域中接近,此方法只会检测到一个峰值,而其他所有峰值则被隐藏。我在网上搜索了几天。有些东西叫做“峰纯度”,“峰分离”。要进行峰分离,有几种方法。它们实际上可以很好地分离峰值。以下是我在网上搜索到的一些图片。
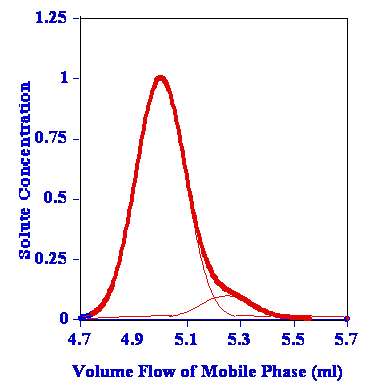
(来源:chromatography-online.org)
{kind=link}
我认为使用“去卷积”方法可能是这种情况下最好的方法。但是我不知道如何去卷积我的频谱,以及如何使用去卷积分离峰值。据我所知,去卷积不会直接给我多个峰值组件,就像上面的图片中看到的那样。我应该使用哪些滤波器函数?由于我缺乏数学技能,因此需要伪代码级别的帮助。欢迎任何其他建议 :)