如何获得pandas数据框df的行数?
19个回答
2778
对于数据框 df,可以使用以下任意一种方法:
len(df.index)df.shape[0]df[df.columns[0]].count()(== 第一列中非NaN值的数量)
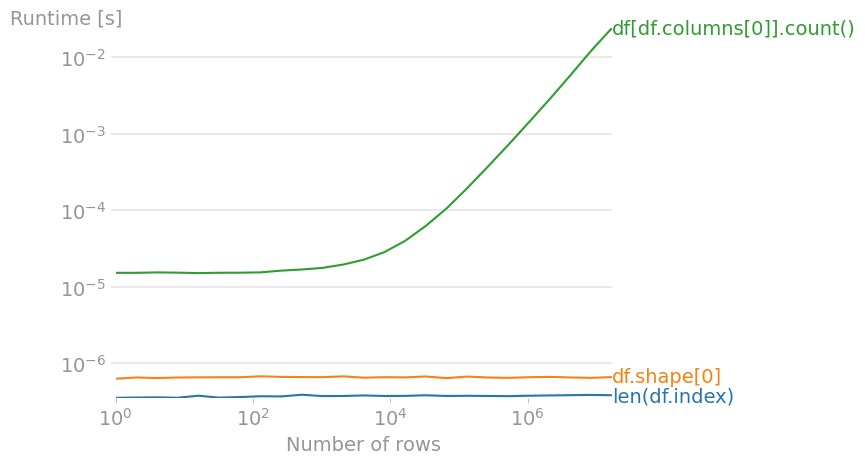
用于重现图表的代码:
import numpy as np
import pandas as pd
import perfplot
perfplot.save(
"out.png",
setup=lambda n: pd.DataFrame(np.arange(n * 3).reshape(n, 3)),
n_range=[2**k for k in range(25)],
kernels=[
lambda df: len(df.index),
lambda df: df.shape[0],
lambda df: df[df.columns[0]].count(),
],
labels=["len(df.index)", "df.shape[0]", "df[df.columns[0]].count()"],
xlabel="Number of rows",
)
- root
19
30在交互式工作中,使用
shape而不是len(df)有一个很好的原因:尝试不同的过滤操作时,我经常需要知道剩余多少项。使用shape后,我可以通过在过滤操作后添加.shape来看到这一点。使用len()会使命令行编辑变得更加麻烦,需要来回切换。 - K.-Michael Aye13对于 OP 来说可能不适用,但如果你只需要知道数据框是否为空,
df.empty 是最好的选择。 - jtschoonhoven22我知道已经有一段时间了,但是len(df.index)需要381纳秒或0.381微秒,而df.shape则慢3倍,需要1.17微秒。我是否漏掉了什么?@root - T.G.
14(3,3)矩阵是一个不好的例子,因为它没有显示形状元组的顺序。 - xaedes
9
df.shape[0]比len(df)或len(df.columns)更快的原因是什么?由于1 ns(纳秒)= 1000 µs(微秒),因此1.17µs = 1170ns,这意味着它大约比381ns慢3倍。 - itsjef显示剩余14条评论
482
假设 df 是你的数据框,那么:
count_row = df.shape[0] # Gives number of rows
count_col = df.shape[1] # Gives number of columns
或者更简洁地说,
r, c = df.shape
- Nasir Shah
7
20如果数据集很大,如果您只需要行数计数,则len(df.index)比df.shape[0]快得多。我进行了测试。 - Sumit Pokhrel
2为什么我的DataFrame上没有shape方法? - Ardalan Shahgholi
2@ArdalanShahgholi 可能是因为返回的是一个序列,它始终是一维的。因此,只有
len(df.index) 才能起作用。 - Connor@ArdalanShahgholi,shape不是一个函数,而是一个属性。您可以通过比较df.shape和df.shape()来发现这一点。 - rubengavidia0x@connor 对于序列,
df.A.shape[0] 或 df.loc[:,'A'].shape[0] 都可以使用。 - rubengavidia0x显示剩余2条评论
271
使用 len(df) :-).
__len__() 的文档中写道“返回索引的长度”。
计时信息,设置方式与root的答案中的设置方式相同:
In [7]: timeit len(df.index)
1000000 loops, best of 3: 248 ns per loop
In [8]: timeit len(df)
1000000 loops, best of 3: 573 ns per loop
因为多了一个函数调用,直接调用 len(df.index) 肯定比调用 len(df) 稍微慢一点。但在大多数情况下这并不重要。我觉得 len(df) 很易读。
- Dr. Jan-Philip Gehrcke
161
如何获取 Pandas DataFrame 的行数?
这张表总结了在 DataFrame(或 Series,为完整起见)中想要计数的不同情况,以及推荐的方法。

脚注
DataFrame.count返回每列的计数作为一个Series,因为非空计数因列而异。DataFrameGroupBy.size返回一个Series,因为同一组中的所有列共享相同的行数。DataFrameGroupBy.count返回一个DataFrame,因为在同一组中,非空计数可以因列而异。要获取特定列的分组非空计数,请使用df.groupby(...)['x'].count(),其中“x”是要计数的列。
最小代码示例
下面,我展示了上述表格中描述的每种方法的示例。首先是设置 -
df = pd.DataFrame({
'A': list('aabbc'), 'B': ['x', 'x', np.nan, 'x', np.nan]})
s = df['B'].copy()
df
A B
0 a x
1 a x
2 b NaN
3 b x
4 c NaN
s
0 x
1 x
2 NaN
3 x
4 NaN
Name: B, dtype: object
DataFrame的行数: len(df)、df.shape[0] 或 len(df.index)
len(df)
# 5
df.shape[0]
# 5
len(df.index)
# 5
在比较常数时间操作的性能时似乎有些愚蠢,尤其是当差异只在“认真的,不用担心”级别上时。但这似乎是其他答案的趋势,为了完整起见,我也这样做。
在上面的三种方法中,len(df.index)(如其他答案中所述)是最快的。
注意
- 上述所有方法均为常数时间操作,因为它们都是简单的属性查找。
df.shape(类似于ndarray.shape)是一个返回元组(# 行数,# 列数)的属性。例如,对于此处的示例,df.shape返回(8, 2)。
DataFrame的列数: df.shape [1],len(df.columns)
df.shape[1]
# 2
len(df.columns)
# 2
与len(df.index)类似,len(df.columns)是两种方法中更快的方法(但需要键入更多字符)。
系列的行数:len(s)、s.size、len(s.index)
len(s)
# 5
s.size
# 5
len(s.index)
# 5
s.size和len(s.index)在速度方面差不多,但我推荐使用len(df)。
注意:
size是一个属性,它返回元素的数量(对于任何Series来说,这意味着行数)。DataFrames也定义了一个size属性,它返回与df.shape[0] * df.shape[1]相同的结果。
非空行计数:DataFrame.count 和 Series.count
此处描述的方法仅计算非空值(即忽略NaN)。
调用DataFrame.count将返回每个列的非NaN计数:
df.count()
A 5
B 3
dtype: int64
对于Series,请使用Series.count来达到类似的效果:
s.count()
# 3
按组计数行数:GroupBy.size
对于DataFrames,使用DataFrameGroupBy.size函数来计算每个组内的行数。
df.groupby('A').size()
A
a 2
b 2
c 1
dtype: int64
同样地,对于Series,您将使用SeriesGroupBy.size。
s.groupby(df.A).size()
A
a 2
b 2
c 1
Name: B, dtype: int64
Series。对于 DataFrames 来说,这也是有意义的,因为所有组共享相同的行数。
按组计算非空行数:GroupBy.count
与上述类似,但使用GroupBy.count, 而不是 GroupBy.size。请注意,size 总是返回一个 Series,而count 如果在特定列上调用,则返回一个 Series ,否则返回一个 DataFrame。
以下方法返回相同的内容:
df.groupby('A')['B'].size()
df.groupby('A').size()
A
a 2
b 2
c 1
Name: B, dtype: int64
同时,对于count,我们有:
df.groupby('A').count()
B
A
a 2
b 1
c 0
在整个GroupBy对象上调用,而不是...
df.groupby('A')['B'].count()
A
a 2
b 1
c 0
Name: B, dtype: int64
在特定的列上调用。
- cs95
2
s.shape[0] 用于获取序列的行数。 - rubengavidia0x你好,能否看一下这个问题:
https://dev59.com/kcPra4cB1Zd3GeqPios5 - Aaditya Ura
80
简而言之,使用 len(df)
len() 函数返回列表(也适用于字典、字符串、元组或区间对象)中的项数(长度)。因此,要获取 DataFrame 的行数,只需使用 len(df)。
有关 len 函数的更多信息,请参见官方页面。
或者,您可以使用 df.index 和 df.columns 分别访问所有行和所有列。由于您可以使用 len(anyList) 获取元素数量,因此使用
len(df.index) 将给出行数,而 len(df.columns) 将给出列数。
或者,您可以使用 df.shape,它将返回行数和列数(作为元组),其中可以使用其索引访问每个项目。如果要访问行数,请仅使用 df.shape [0]。对于列数,请仅使用:df.shape [1]。
- Memin
2
3@BrendanMetcalfe,我不知道你的数据框有什么问题,没有看到它的数据。您可以检查脚本末尾以查看,确实
len可用于获取行数。这是脚本链接:https://onecompiler.com/python/3xc9nuvrx - Memin我无法理解为什么
df.shape 不比 len 更快,因为它只需要获取 shape 属性而不调用函数 __len__。 - CutePoison25
除了之前的回答,您可以使用df.axes来获取包含行和列索引的元组,然后使用len()函数:
除了之前的回答,您可以使用
df.axes来获取包含行和列索引的元组,然后使用len()函数:total_rows = len(df.axes[0])
total_cols = len(df.axes[1])
- Nik
1
5这会返回索引对象,它们可能是原始对象的副本,如果你只是在检查长度后将它们丢弃,这样做是浪费的。除非你打算对索引执行其他操作,否则 不要使用。 - cs95
15
...在Jan-Philip Gehrcke的回答的基础上构建。
为什么len(df)或len(df.index)比df.shape[0]更快:
看这段代码。df.shape是一个@property,调用了len两次运行DataFrame方法。
df.shape??
Type: property
String form: <property object at 0x1127b33c0>
Source:
# df.shape.fget
@property
def shape(self):
"""
Return a tuple representing the dimensionality of the DataFrame.
"""
return len(self.index), len(self.columns)
在 len(df) 的背后
df.__len__??
Signature: df.__len__()
Source:
def __len__(self):
"""Returns length of info axis, but here we use the index """
return len(self.index)
File: ~/miniconda2/lib/python2.7/site-packages/pandas/core/frame.py
Type: instancemethod
len(df.index) 比 len(df) 稍微快一点,因为它少了一个函数调用,但是这总是比 df.shape[0] 更快
- debo
2
2语法高亮似乎不太对。你能修复一下吗?例如,这是输出、代码和注释的混合体吗(这不是一个反问)? - Peter Mortensen
@PeterMortensen 这个输出来自于ipython/jupyter。执行一个函数名并在后面加上两个问号而不带括号将会显示该函数的定义。例如,对于函数
len(),你可以执行len??。 - debo14
对于一个数据框 df:
当你还在编写代码时:
len(df)df.shape[0]
代码完成后最快的一次:
len(df.index)
在正常数据大小下,每个选项都会在不到一秒钟内完成。因此,“最快”的选项实际上是让您工作最快的选项,如果您已经有一个子集df并且想要在交互式会话中简要添加.shape[0],那么可以是len(df)或df.shape[0]。
在最终优化的代码中,最快的运行时间是len(df.index)。
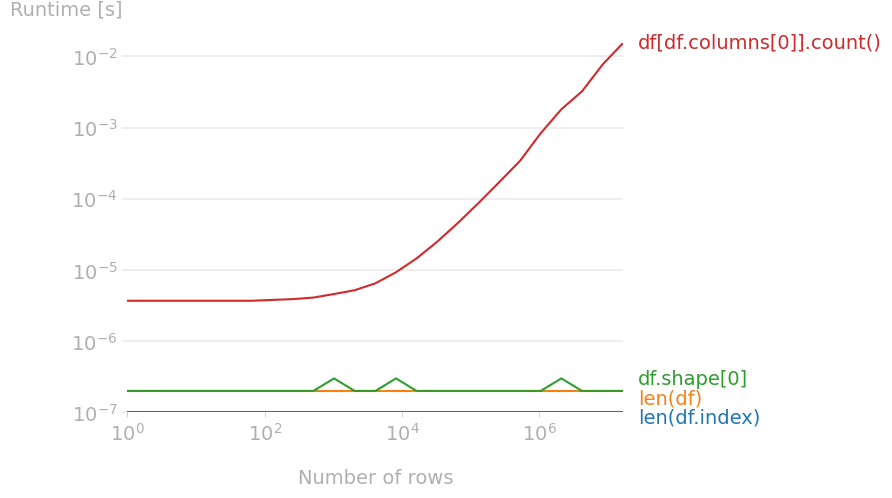
df[df.columns[0]].count(),因为没有评论者指出它有用的情况。它的速度是指数级的缓慢,而且输入起来很长。它提供了第一列中非 NaN 值的 number of non-NaN values。重现图表的代码:
pip install pandas perfplot
import numpy as np
import pandas as pd
import perfplot
perfplot.save(
"out.png",
setup=lambda n: pd.DataFrame(np.arange(n * 3).reshape(n, 3)),
n_range=[2**k for k in range(25)],
kernels=[
lambda df: len(df.index),
lambda df: len(df),
lambda df: df.shape[0],
lambda df: df[df.columns[0]].count(),
],
labels=["len(df.index)", "df.shape[0]", "df[df.columns[0]].count()"],
xlabel="Number of rows",
)
- Jimmy Carter
1
我已经尝试了两次改进被接受的答案,但两次都被拒绝了。被接受的答案不清楚且冗长,没有直接告诉人们最快的方法。它也没有提到
len(df) 或 df[df.columns[0]].count() 的任何目的。 - Jimmy Carter11
我来自R背景,学习Pandas时发现在选择行或列方面更加复杂。
我必须花费一些时间去解决它,然后我找到了一些处理方法:
获取列数:
获取行数:
我必须花费一些时间去解决它,然后我找到了一些处理方法:
获取列数:
len(df.columns)
## Here:
# df is your data.frame
# df.columns returns a string. It contains column's titles of the df.
# Then, "len()" gets the length of it.
获取行数:
len(df.index) # It's similar.
- Catbuilts
1
使用* Pandas *一段时间后,我认为我们应该使用
df.shape。它分别返回行数和列数。 - Chau Pham8
如果您想在链接操作的中途获取行数,请使用以下方法:
df.pipe(len)
例子:
row_count = (
pd.DataFrame(np.random.rand(3,4))
.reset_index()
.pipe(len)
)
如果您不想在len()函数中放入一个很长的声明,那么这可能会很有用。
您可以使用__len__()代替,但__len__()看起来有点奇怪。
- Allen Qin
1
2似乎想要“管道”这个操作是毫无意义的,因为你没有其他可以将其传递的内容(它返回一个整数)。我更愿意使用
count = len(df.reset_index())而不是count = df.reset_index().pipe(len)。前者只是属性查找,没有函数调用。 - cs95网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 6 如何获取pandas dataframe对象值的模式?
- 7 如何为Pandas DataFrame中的最大函数设置行数限制
- 47 如何使用pandas dataframe获取tfidf?
- 17 获取Pandas DataFrame的第一列
- 3 Pandas:获取动态行数的平均值
- 4 Python Polars:如何获取DataFrame的行数?
- 241 如何获取 pandas DataFrame 的最后 N 行?
- 4 Python - Pandas - DataFrame 减少行数
- 111 获取 pandas DataFrame 的名称
- 9 如何创建指定行数和列数的 pandas 数据框(DataFrame)
df.count()只会返回每列中非 NA/NaN 行的数量。您应该使用df.shape[0],它将始终正确地告诉您行数。 - smci