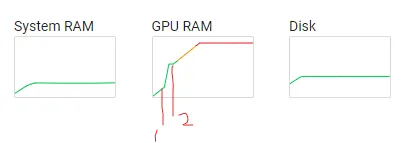
据我所知,在使用GPU进行模型训练和验证时,GPU内存主要用于加载数据,前向传播和反向传播。据我所知,GPU内存使用应该在以下情况下相同:1)训练前,2)训练后,3)验证前,4)验证后。但在我的情况下,验证阶段使用的GPU内存仍然被占用于训练阶段,反之亦然。它不会每个epoch增加,因此我确定它不是像loss.item()这样的常见错误。
这是我的问题摘要:
- 在一个阶段中使用的GPU内存不应该在另一个阶段之前清理(除了模型权重)吗? - 如果应该,那么我是否犯了任何初学者的错误?
感谢您的帮助。
以下是训练循环的代码:
这是我的问题摘要:
- 在一个阶段中使用的GPU内存不应该在另一个阶段之前清理(除了模型权重)吗? - 如果应该,那么我是否犯了任何初学者的错误?
感谢您的帮助。
以下是训练循环的代码:
eval_result = evaluate(model,val_loader,True,True)
print(eval_result)
print('start training')
for epoch in range(num_epoch):
model.train()
time_ = datetime.datetime.now()
for iter_, data in enumerate(tr_loader):
x, y = data
x = x.to(device).view(x.shape[0],1,*(x.shape[1:]))
y = y.to(device).long()
pred = model.forward(x)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print
print_iter = 16
if (iter_+1) % print_iter == 0:
elapsed = datetime.datetime.now() - time_
expected = elapsed * (num_batches / print_iter)
_epoch = epoch + ((iter_ + 1) / num_batches)
print('\rTRAIN [{:.3f}/{}] loss({}) '
'elapsed {} expected per epoch {}'.format(
_epoch,num_epoch, loss.item(), elapsed, expected)
,end="\t\t\t")
time_ = datetime.datetime.now()
print()
eval_result = evaluate(model,val_loader,True,True)
print(eval_result)
scheduler.step(eval_result[0])
if (epoch+1) %1 == 0:
save_model(model, optimizer, scheduler)
我了解,将验证阶段作为函数可以帮助 python 函数作用域的语言特性。因此,evaluate() 函数是:
def evaluate(model, val_loader, get_acc = True, get_IOU = True):
"""
pred: Tensor of shape B C D H W
label Tensor of shape B D H W
"""
val_loss = 0
val_acc = 0
val_IOU = 0
with torch.no_grad():
model.eval()
for data in tqdm(val_loader):
x, y = data
x = x.to(device).view(x.shape[0],1,*(x.shape[1:]))
y = y.to(device).long()
pred = model.forward(x)
loss = loss_fn(pred,y)
val_loss += loss.item()
pred = torch.argmax(pred, dim=1)
if get_acc:
total = np.prod(y.shape)
total = total if total != 0 else 1
val_acc += torch.sum((pred == y)).cpu().item()/total
if get_IOU:
iou = 0
for class_num in range(1,8):
iou += torch.sum((pred==class_num)&(y==class_num)).cpu().item()\
/ torch.sum((pred==class_num)|(y==class_num)).cpu().item()
val_IOU += iou/7
val_loss /= len(val_loader)
val_acc /= len(val_loader)
val_IOU /= len(val_loader)
return (val_loss, val_acc, val_IOU)
这里展示了在colab中的GPU使用情况。1是第一次调用evaluate()的时间点,2是训练开始的时间点。