我正在尝试使用Huggingface Transformer模块逐句编码文档。我正在使用非常小的预训练模型
在我的本地GTX 1060 3GB上进行大约200-300次迭代后,我会收到一个错误消息,指出我的CUDA内存已满。在具有更多GPU RAM的Colab上运行此代码可进行数千次迭代。
我尝试过以下方法:
- 在每次迭代的开头添加torch.cuda.empty_cache()以清除先前保存的张量 - 将模型包装在torch.no_grad()中以禁用计算图 - 设置model.eval()以禁用可能占用内存的任何随机属性 - 将输出直接发送到CPU以释放内存
我对为什么我的内存不断溢出感到困惑。我已经训练了几个更大的模型,并应用了所有标准的训练循环实践(optimizer.zero_grad()等)。我从未遇到过这个问题。为什么这个看似微不足道的任务会出现这个问题?
google/bert_uncased_L-2_H-128_A-2,并使用以下代码:def pre_encode_wikipedia(model, tokenizer, device, save_path):
document_data_list = []
for iteration, document in enumerate(wikipedia_small['text']):
torch.cuda.empty_cache()
sentence_embeds_per_doc = [torch.randn(128)]
attention_mask_per_doc = [1]
special_tokens_per_doc = [1]
doc_split = nltk.sent_tokenize(document)
doc_tokenized = tokenizer.batch_encode_plus(doc_split, padding='longest', truncation=True, max_length=512, return_tensors='pt')
for key, value in doc_tokenized.items():
doc_tokenized[key] = doc_tokenized[key].to(device)
with torch.no_grad():
doc_encoded = model(**doc_tokenized)
for sentence in doc_encoded['last_hidden_state']:
sentence[0].to('cpu')
sentence_embeds_per_doc.append(sentence[0])
attention_mask_per_doc.append(1)
special_tokens_per_doc.append(0)
sentence_embeds = torch.stack(sentence_embeds_per_doc)
attention_mask = torch.FloatTensor(attention_mask_per_doc)
special_tokens_mask = torch.FloatTensor(special_tokens_per_doc)
document_data = torch.utils.data.TensorDataset(*[sentence_embeds, attention_mask, special_tokens_mask])
torch.save(document_data, f'{save_path}{time.strftime("%Y%m%d-%H%M%S")}{iteration}.pt')
print(f"Document at {iteration} encoded and saved.")
在我的本地GTX 1060 3GB上进行大约200-300次迭代后,我会收到一个错误消息,指出我的CUDA内存已满。在具有更多GPU RAM的Colab上运行此代码可进行数千次迭代。
我尝试过以下方法:
- 在每次迭代的开头添加torch.cuda.empty_cache()以清除先前保存的张量 - 将模型包装在torch.no_grad()中以禁用计算图 - 设置model.eval()以禁用可能占用内存的任何随机属性 - 将输出直接发送到CPU以释放内存
我对为什么我的内存不断溢出感到困惑。我已经训练了几个更大的模型,并应用了所有标准的训练循环实践(optimizer.zero_grad()等)。我从未遇到过这个问题。为什么这个看似微不足道的任务会出现这个问题?
编辑 #1
将 sentence[0].to('cpu') 改为 cpu_sentence = sentence[0].to('cpu') 后,我能够进行几千次迭代,但突然 VRAM 的使用量激增,导致程序崩溃: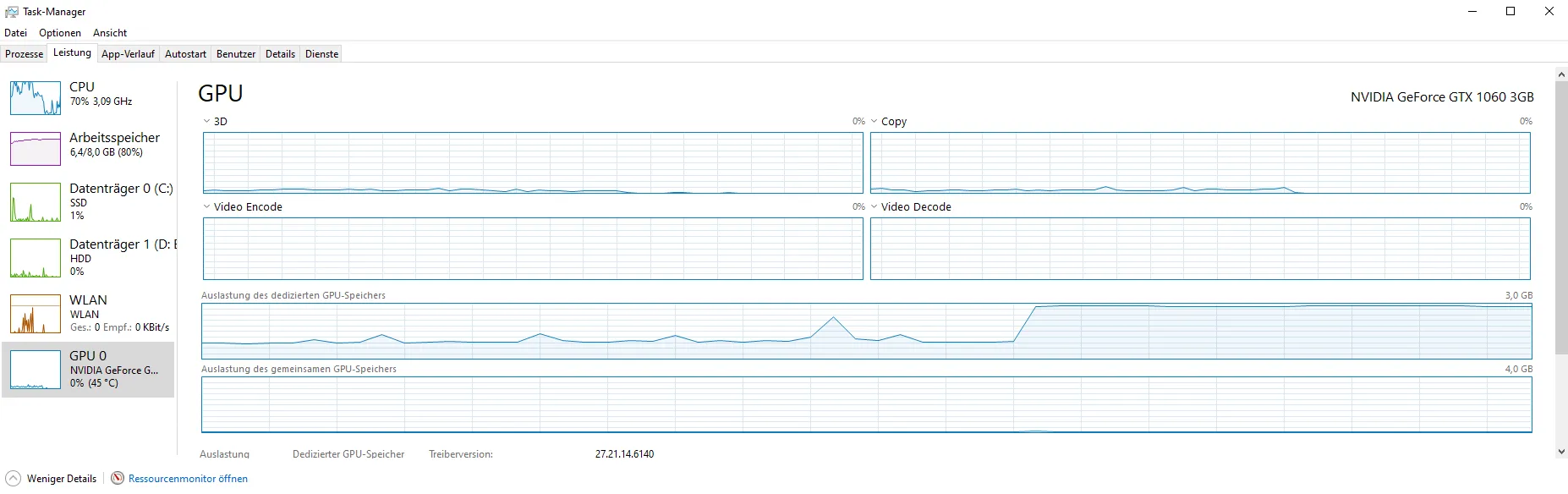
sentence[0].to('cpu')不会将你的张量移动到'cpu',而是会创建一个副本。你能检查一下吗? - Ivan