我正在尝试使用tidyr将数据从宽格式转换为长格式,但也愿意尝试其他选项。这是一个带有重复值的虚假数据集,但其结构与真实数据集相同。
structure(list(Category = c("Pre", "Pre", "Pre", "post_med_1",
"post_med_1", "post_med_1", "post_med_2", "post_med_2", "post_med_2"
), Time = c(1L, 2L, 3L, 1L, 2L, 3L, 1L, 2L, 3L), Subj_1_tox = c(4.2,
5, 2.3, 4.2, 5, 2.3, 4.2, 5, 2.3), Subj_2_tox = c(23L, 1L, 4L,
23L, 1L, 4L, 23L, 1L, 4L), Subj_3_tox = c(6, 4.9, 3.2, 6, 4.9,
3.2, 6, 4.9, 3.2), Subj_1_a1 = c(4.2, 5, 2.3, 4.2, 5, 2.3, 4.2,
5, 2.3), Subj_2_a1 = c(23L, 1L, 4L, 23L, 1L, 4L, 23L, 1L, 4L),
Subj_3_a1 = c(6, 4.9, 3.2, 6, 4.9, 3.2, 6, 4.9, 3.2)), class = "data.frame", row.names = c(NA,
-9L))
让我感到困惑的是如何在一个调用中将tox列和a1列转换为长格式并保留类别和时间列。首先是名称模式的正则表达式。我已经查找了正则表达式模式,但不清楚如何获得它,其次如何在一个调用中包含2个不同的值列?
基本上在一个调用中做类似于这样的事情。
df_longer<-df %>%
pivot_longer(
cols=contains("tox") & contains("a1"),
names_to = c("subject", "tox", "a1"),
names_pattern = "(Subj_['all_numbers') (tox and a1) "
values_to = c("tox_value", "a1"))
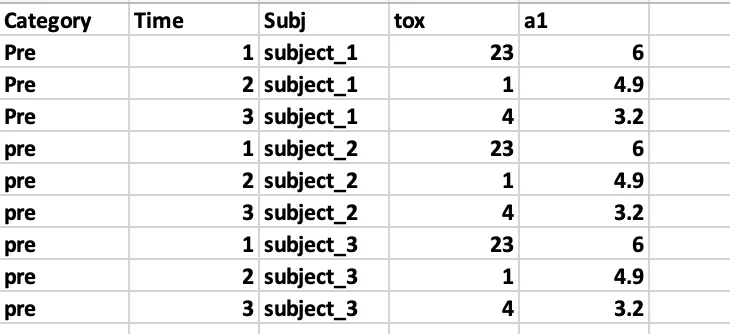
最终结果应该是Subject(#)在名为subject的一列中,tox值和a1值分别在其他列中。是否可以在一次调用中完成此操作?我也可以接受其他解决方案,但我正在尝试更多地了解tidyr。最终结果应该类似于这样,但此示例中的值不正确,但其他部分准确。
”在.value`中的作用是什么? - rj44.value表示原始数据框中的部分列名将包含新的列名。我们在names_pattern中定义这一部分。 - Ronak Shah