概述
为什么需要复制并交换惯用语?
任何管理资源(像智能指针这样的wrapper)的类都需要实现三大函数。虽然复制构造函数和析构函数的目标和实现很简单,但是复制赋值运算符可能是最微妙和最困难的。应该如何执行它?需要避免哪些陷阱?
复制并交换惯用语就是解决方案,并优雅地帮助赋值运算符实现两个目标:避免代码重复和提供强异常保证。
它是如何工作的?
从概念上讲,它通过使用复制构造函数的功能创建数据的本地副本,然后使用swap函数获取已复制的数据,将旧数据与新数据交换。然后临时副本被销毁,带走了旧数据。我们留下了新数据的副本。
为了使用复制并交换惯用语,我们需要三件事:一个可以正常工作的复制构造函数,一个可以正常工作的析构函数(两者都是任何包装器的基础,因此应该完整),以及一个swap函数。
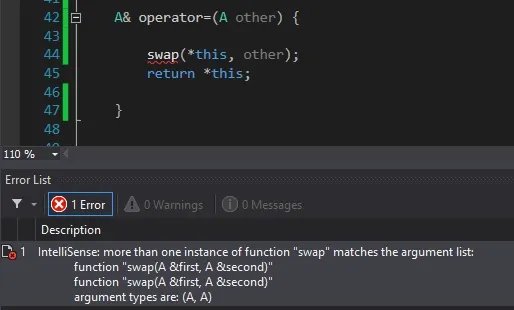
一个交换函数是一个不抛出异常的函数,它按成员逐个交换两个类的对象。我们可能会想使用std::swap而不是提供我们自己的函数,但这是不可能的;std::swap在其实现中使用复制构造函数和复制赋值运算符,最终我们将试图根据自身定义赋值运算符!(不仅如此,而且对swap的未限定调用将使用我们自定义的swap运算符,跳过无需进行的类构造和销毁,这些操作在std::swap中必要。)
深入解释
目标
让我们考虑一个具体的案例。我们想要在一个无用的类中管理动态数组。我们从一个可用的构造函数、拷贝构造函数和析构函数开始:
#include <algorithm>
#include <cstddef>
class dumb_array
{
public:
dumb_array(std::size_t size = 0)
: mSize(size),
mArray(mSize ? new int[mSize]() : nullptr)
{
}
dumb_array(const dumb_array& other)
: mSize(other.mSize),
mArray(mSize ? new int[mSize] : nullptr)
{
std::copy(other.mArray, other.mArray + mSize, mArray);
}
~dumb_array()
{
delete [] mArray;
}
private:
std::size_t mSize;
int* mArray;
};
这个类几乎成功地管理了数组,但需要 operator= 来正确工作。
一个失败的解决方案
以下是一个天真实现的样子:
dumb_array& operator=(const dumb_array& other)
{
if (this != &other)
{
delete [] mArray;
mArray = nullptr;
mSize = other.mSize;
mArray = mSize ? new int[mSize] : nullptr;
std::copy(other.mArray, other.mArray + mSize, mArray);
}
return *this;
}
我们说我们完成了;现在它可以管理一个数组,没有泄漏。然而,它有三个问题,按顺序在代码中标记为(n)。
The first is the self-assignment test.
This check serves two purposes: it's an easy way to prevent us from running needless code on self-assignment, and it protects us from subtle bugs (such as deleting the array only to try and copy it). But in all other cases it merely serves to slow the program down, and act as noise in the code; self-assignment rarely occurs, so most of the time this check is a waste.
It would be better if the operator could work properly without it.
The second is that it only provides a basic exception guarantee. If new int[mSize] fails, *this will have been modified. (Namely, the size is wrong and the data is gone!)
For a strong exception guarantee, it would need to be something akin to:
dumb_array& operator=(const dumb_array& other)
{
if (this != &other)
{
std::size_t newSize = other.mSize;
int* newArray = newSize ? new int[newSize]() : nullptr;
std::copy(other.mArray, other.mArray + newSize, newArray);
delete [] mArray;
mSize = newSize;
mArray = newArray;
}
return *this;
}
The code has expanded! Which leads us to the third problem: code duplication.
我们的赋值运算符有效地复制了我们已经在其他地方编写的所有代码,这是一件可怕的事情。
在我们的情况下,它的核心只有两行(分配和复制),但对于更复杂的资源,这种代码膨胀可能会带来很多麻烦。我们应该努力避免重复自己。
(有人可能会想:如果管理一个资源需要这么多代码,那么如果我的类管理多个资源呢?
虽然这似乎是一个合理的关注点,并且确实需要非平凡的try/catch子句,但这不是问题。
那是因为一个类应该只管理
一个资源!)
成功的解决方案
如上所述,复制并交换惯用语将解决所有这些问题。但现在,我们除了一个swap函数之外,已经具备了所有要求。尽管三法则成功地包含了我们的复制构造函数、赋值运算符和析构函数的存在,但它真的应该被称为“Three and A Half”:每当你的类管理一个资源时,提供一个swap函数也是有意义的。
我们需要向我们的类添加交换功能,我们可以按照以下方式进行:
class dumb_array
{
public:
friend void swap(dumb_array& first, dumb_array& second)
{
using std::swap;
swap(first.mSize, second.mSize);
swap(first.mArray, second.mArray);
}
};
(这里是关于public friend swap的解释。)现在我们不仅可以交换dumb_array,而且一般情况下交换可以更有效率; 它只是交换指针和大小,而不是分配和复制整个数组。除了这个额外的功能和效率之外,我们现在已经准备好实现拷贝并交换惯用法。
话不多说,我们的赋值运算符是:
dumb_array& operator=(dumb_array other)
{
swap(*this, other);
return *this;
}
就是这样!一举三得,所有问题都被优雅地解决了。
为什么它有效?
我们首先注意到一个重要的选择:参数参数是通过值传递的。虽然可以轻松地执行以下操作(实际上,许多天真的惯用语实现都会这样做):
dumb_array& operator=(const dumb_array& other)
{
dumb_array temp(other);
swap(*this, temp);
return *this;
}
我们失去了一个
重要的优化机会。不仅如此,而且这个选择在C++11中非常关键,稍后会讨论。 (总的来说,一个非常有用的准则是:如果你要在函数中复制某些东西,请让编译器在参数列表中完成它。‡)
无论哪种方式,获取资源的这种方法是消除代码重复的关键:我们可以使用从复制构造函数中获得的代码进行复制,而且永远不需要重复任何代码。现在,副本已经创建好了,我们准备交换。
请注意,在进入函数时,所有新数据都已分配、复制并准备好使用。这就是为什么我们可以免费获得强异常保证的原因:如果复制构造失败,我们甚至不会进入函数,因此不可能改变
*this的状态。(我们以前为了获得强异常保证所做的事情,现在编译器正在为我们完成;多么善良。)
此时,我们已经安全地修改了状态,因为
swap是不抛出异常的。我们将当前数据与复制的数据交换,旧数据被放入临时变量中。当函数返回时,旧数据被释放。(然后参数的作用域结束,调用其析构函数。)
因为这个习语没有重复的代码,所以我们不能在操作符中引入错误。请注意,这意味着我们不需要进行自我分配检查,允许单一统一实现
operator=。(此外,我们也不再对非自我分配产生性能损失。)
这就是复制和交换惯用法。
C++11又有什么不同呢?
C++的下一个版本,C++11,对我们如何管理资源做了一个非常重要的改变:三大法则现在成为四个半法则了。为什么?因为我们不仅需要能够复制构造我们的资源,
我们还需要移动构造它。
幸运的是,这很容易:
class dumb_array
{
public:
dumb_array(dumb_array&& other) noexcept ††
: dumb_array()
{
swap(*this, other);
}
};
这里发生了什么?回想一下移动构造的目标:从类的另一个实例中获取资源,使其保持可分配和可销毁状态。
所以我们所做的很简单:通过默认构造函数(C++11功能)进行初始化,然后与“other”交换;我们知道我们的类的默认构造实例可以安全地被赋值和销毁,因此在交换后,我们知道“other”将能够做到同样的事情。
(请注意,某些编译器不支持构造函数委托;在这种情况下,我们必须手动默认构造该类。这是不幸但幸运的琐事。)
为什么有效?
我们需要对我们的类进行唯一的更改,那么为什么它有效呢?记住我们所做的重要决定,将参数作为值而不是引用:
dumb_array& operator=(dumb_array other); // (1)
现在,如果
other正在使用rvalue进行初始化,
它将会被move-constructed(移动构造)。太好了。与C++03以通过按值传递参数来重复使用我们的copy-constructor功能方式一样,C++11也会在适当的时候
自动选择move-constructor。(当然,正如先前链接的文章中所提到的,值的复制/移动也可能完全不被执行。)
因此,拷贝并交换惯用法就这样结束了。
脚注
*为什么要将mArray设置为null?因为如果操作符中的任何进一步代码抛出异常,则可能会调用dumb_array的析构函数;如果这种情况发生而没有将其设置为null,我们将尝试删除已经删除的内存!通过将其设置为null,我们避免了这种情况,因为删除null是无操作。
†还有其他说法认为我们应该专门针对我们的类型进行std::swap的特化,提供一个类内的swap和一个自由函数swap等等。但这些都是不必要的:任何正确使用swap的方式都将通过未限定的调用进行,而我们的函数将通过ADL被找到。只需要一个函数。
‡原因很简单:一旦你拥有了资源,你可以在参数列表中复制它,然后将其交换和/或移动(C++11)到需要的任何地方。通过在参数列表中进行复制,最大化优化。
††移动构造函数通常应该是noexcept,否则某些代码(例如std::vector调整大小逻辑)即使在移动有意义时也将使用复制构造函数。当然,只有在内部的代码不会抛出异常时才将其标记为noexcept。