我有一些旧的迁移文件,其中包含不可打印的字符。我想找到所有这样命名的文件并从系统中彻底删除它们。
例子:
ls -l
-rwxrwxr-x 1 cws cws 0 Dec 28 2011 ??"??
ls -lb
-rwxrwxr-x 1 cws cws 0 Dec 28 2011 \a\211"\206\351
我想找到所有这样的文件。
这是一个示例截图,显示了当我在这些文件夹中执行ls命令时看到的内容:
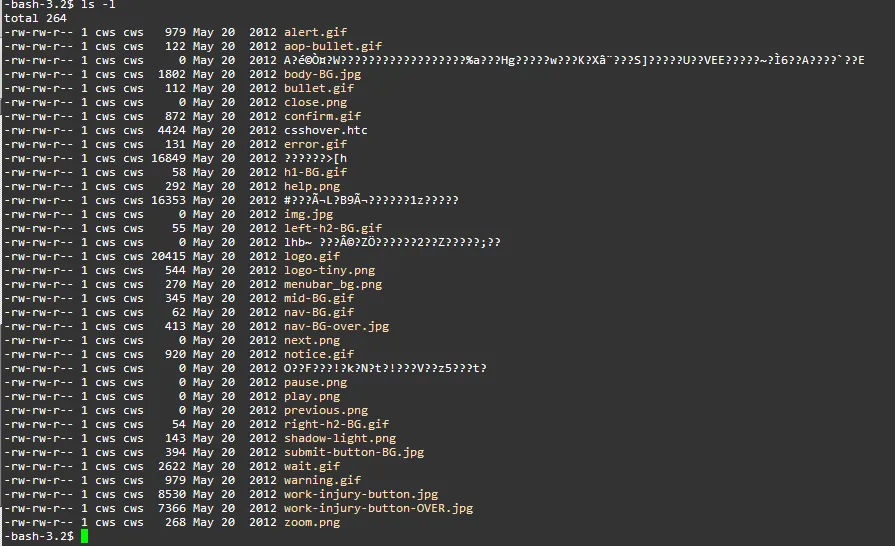
我想找到带有不可打印字符的文件,并将其删除。
ASCII字符代码的范围从十六进制的0x00到0x7F。因此,任何代码大于0x7F的字符都是非ASCII字符。这包括UTF-8中的大部分字符(ASCII代码本质上是UTF-8的子集)。例如,日语字符
あ
在UTF-8中,E3 81 82以十六进制编码。
E3 81 82
UTF-8自Red Hat Linux 8.0版(2002年)、SuSE Linux 9.1版(2004年)和Ubuntu Linux 5.04版(2005年)以来一直是默认的字符编码。
在ASCII代码中,0x00至0x1F和0x7F表示控制字符,例如ESC(0x1B)。这些控制字符最初并不是可打印的,尽管其中一些,如换行符0x0A,可以被解释并显示。
ls将所有控制字符显示为?,除非我使用--show-control-chars选项。我猜想你想要删除的文件包含ASCII控制字符,而不是非ASCII字符。这是一个重要的区别:如果你删除包含非ASCII字符的文件名,可能会误删一些只是用其他语言命名的合法文件。
POSIX提供了一组非常方便的字符类来处理这些类型的字符(感谢bashophil指出这一点):
[:cntrl:] Control characters
[:graph:] Graphic printable characters (same as [:print:] minus the space character)
[:print:] Printable characters (same as [:graph:] plus the space character)
Perl兼容正则表达式(Perl Compatible Regular Expressions)允许使用语法表示十六进制字符编码。
\x00
あ的PCRE正则表达式如下:\xE3\x81\x82
[:ascii:]字符类,它是[\x00-\x7F]的方便简写。grep支持使用-P标志的PCRE,但BSD grep(例如在Mac OS X上)不支持。 GNU和BSD的find都不支持PCRE正则表达式。
find支持POSIX正则表达式(感谢iscfrc指出了纯find解决方案以避免生成其他进程)。以下命令将列出当前目录下包含非可打印控制字符的所有文件名(但不包括目录名):find -type f -regextype posix-basic -regex '^.*/[^/]*[[:cntrl:]][^/]*$'
find -type f -regextype posix-basic -regex '^.*/[^/]*[[:cntrl:]][^/]*$' -delete
-delete选项的命令,这样你就可以在为时已晚之前看到将要被删除的内容。-print选项,你可以在命令运行时看到将要被删除的内容。find -type f -regextype posix-basic -regex '^.*/[^/]*[[:cntrl:]][^/]*$' -print -delete
find -regextype posix-basic -regex '.*[[:cntrl:]].*' -print -delete
看起来您的文件包含非ASCII字符和ASCII控制字符。事实证明,[:ascii:]不是POSIX字符类,但它由PCRE提供。我找不到一个POSIX正则表达式来做这件事,所以Perl来解救。我们仍然会使用find来遍历我们的目录树,但我们将把结果传递给Perl进行处理。
为了确保我们可以处理包含换行符的文件名(在这种情况下似乎很可能),我们需要使用-print0参数来调用find(在GNU和BSD版本上都受支持);这将使用空字符(0x00)而不是换行符分隔记录,因为空字符是Linux上不能出现在有效文件名中的唯一字符。我们需要向我们的Perl代码传递相应的标志-0,以便它知道如何分隔记录。以下命令将递归打印当前目录中的每个路径:
find . -print0 | perl -n0e 'print $_, "\n"'
find中,起始路径参数(在本例中为。)是可选的,但在Mac OS X上的BSD find中是必需的,因此我已将其包含以确保可移植性。[[:^ascii:][:cntrl:]]
find . -print0 | perl -n0e 'chomp; print $_, "\n" if /[[:^ascii:][:cntrl:]]/'
chomp是必需的,因为它从每个路径中剥离尾随的空字符,否则将与我们的正则表达式匹配。要删除匹配的文件和目录,我们可以使用以下内容:
find . -print0 | perl -MFile::Path=remove_tree -n0e 'chomp; remove_tree($_, {verbose=>1}) if /[[:^ascii:][:cntrl:]]/'
这也会在命令运行时打印出被删除的内容(尽管控制字符会被解释,因此输出结果不会完全匹配 ls 的输出)。
根据这个答案,尝试:
LC_ALL=C find . -regex '.*[^ -~].*' -print # -delete
或者:
LC_ALL=C find . -type f -regex '*[^[:alnum:][:punct:]]*' -print # -delete
注意:文件正确打印后,请删除#字符。
另请参阅:如何grep所有非ASCII字符。
ls -1 -R -i | grep -a "[^A-Za-z0-9_.':@ /-]" | while read f; do inode=$(echo "$f" | cut -d ' ' -f 1); find -inum "$inode" -delete; done
分解为若干部分:
ls -1 -R -i
这将以递归方式 (-R) 列出当前目录下的文件 (ls),每行一个文件 (-1),并在每个文件前加上其inode号码 (-i)。结果将通过管道传输到 grep。
grep -a "[^A-Za-z0-9_.':@ /-]"
考虑每个输入都是文本(-a),即使最终是二进制的也要这么做。grep会让包含与列表中指定字符不同的字符的行通过。结果将被管道传输到while。
while read f
do
inode=$(echo "$f" | cut -d ' ' -f 1)
find -inum "$inode" -delete
done
这个while循环将遍历所有条目,提取i节点号并将i节点传递给find,然后删除文件。
可以使用PCRE与grep -P一起使用,但不可与find一起使用(遗憾的是)。您可以使用exec将find与grep链接起来。使用PCRE(perl regex),我们可以使用ascii类并查找任何非ascii字符。
find . -type f -exec sh -c "echo \"{}\" | grep -qP '[^[:ascii:]]'" \; -exec rm {} \;
你可以使用grep打印只包含反斜杠的行:
ls -lb | grep \\\\
[:print:]或[:graph:],请参见http://www.faqs.org/docs/abs/HTML/regexp.html。 - EverythingRightPlace[:ascii:]并非完全符合 POSIX。请查看我的更新以获取另一种解决方案。 - ThisSuitIsBlackNot-type f的情况下,添加-mindepth 1可能是有意义的,以免删除目录本身 :) - x-yuri