我编写了一个测试函数来推断有关动态分配的一些更具体的细节。该函数位于答案底部。
该函数调用多个位置函数,这些函数从不同长度的对数间隔输入x计算值y。这些函数在循环类型(for和while)和分配方案(动态和预分配)上有所不同。结果来自R2014b。
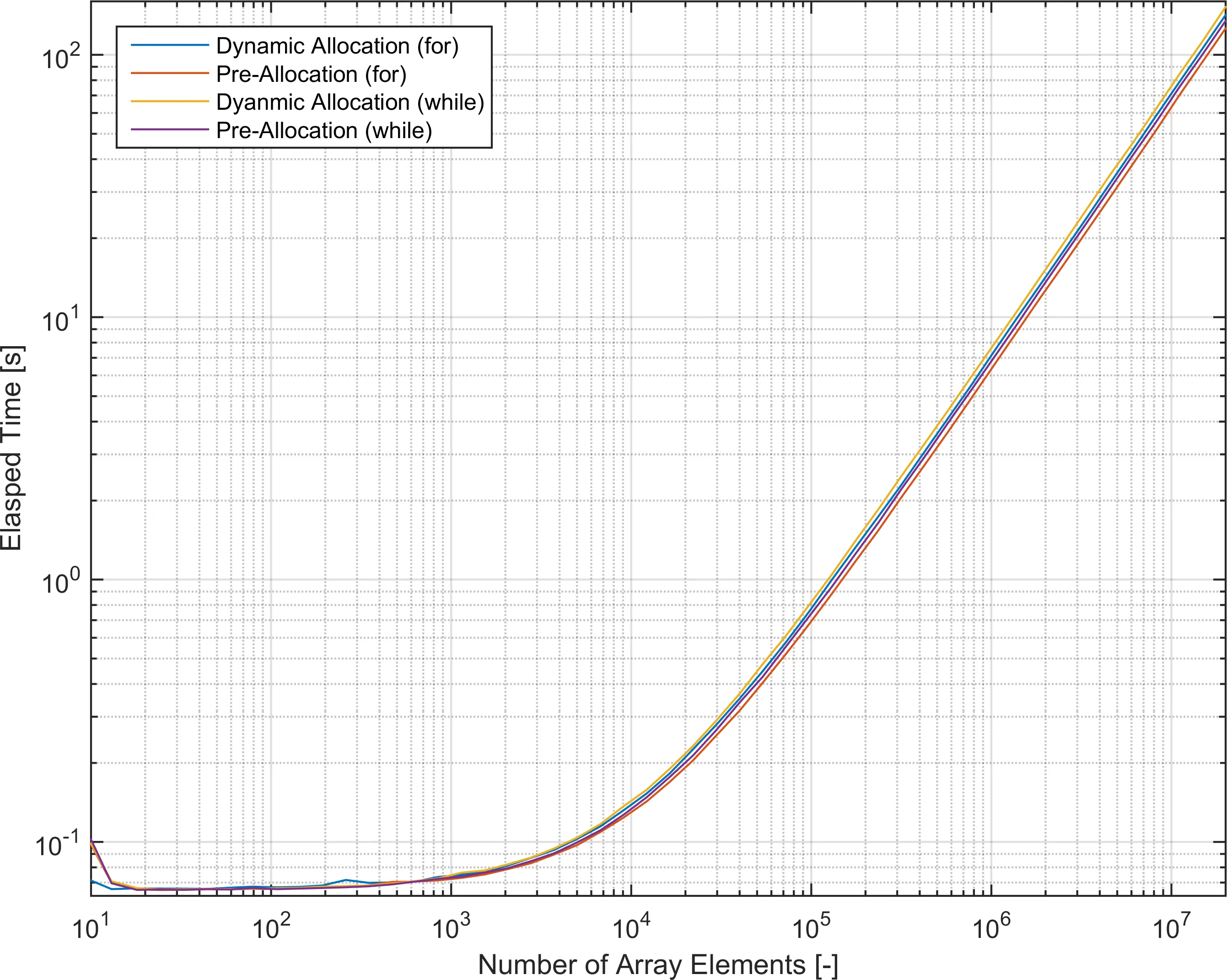
四个函数的经过时间结果如下所示。
对于低元素计数,运行时间是恒定的;对于高元素计数,所有四个函数都进入具有类似增长率的增长模式。
数据的幂次拟合(即c = ArgMin[c(1)*n^c(2) - time])返回指数范围为0.93-0.96(线性增长),跨越四个数据集。
我对这些结果感到非常惊讶,因为要么我在测试中漏掉了某些东西,要么Matlab的JIT编译器非常擅长分配数组(可能在幕后使用链表)。
预分配的for循环的运行速度最快,但仅比动态版本快12%。
转向内存消耗,我在数百万元素范围内运行了动态和预分配版本的
for循环变体,以进行线性增加的元素计数。Matlab使用的总内存在循环开始和结束时进行采样。结果如下所示。
如图所示,两个函数之间的函数调用起始内存相同(大多数情况下)。预分配版本的内存使用量随着元素计数呈线性增长,这是预期的。但是动态版本使用的内存虽然仍然是分段和趋势线性的,但在几个点上具有内存斜率跳跃。对我来说,这意味着Matlab正在执行某种表格增长(不一定像我认为的Python那样进行表格倍增),以避免在每次迭代中重新分配数组(这确实使我对上面的经过时间讨论中的链表想法产生了疑问)。
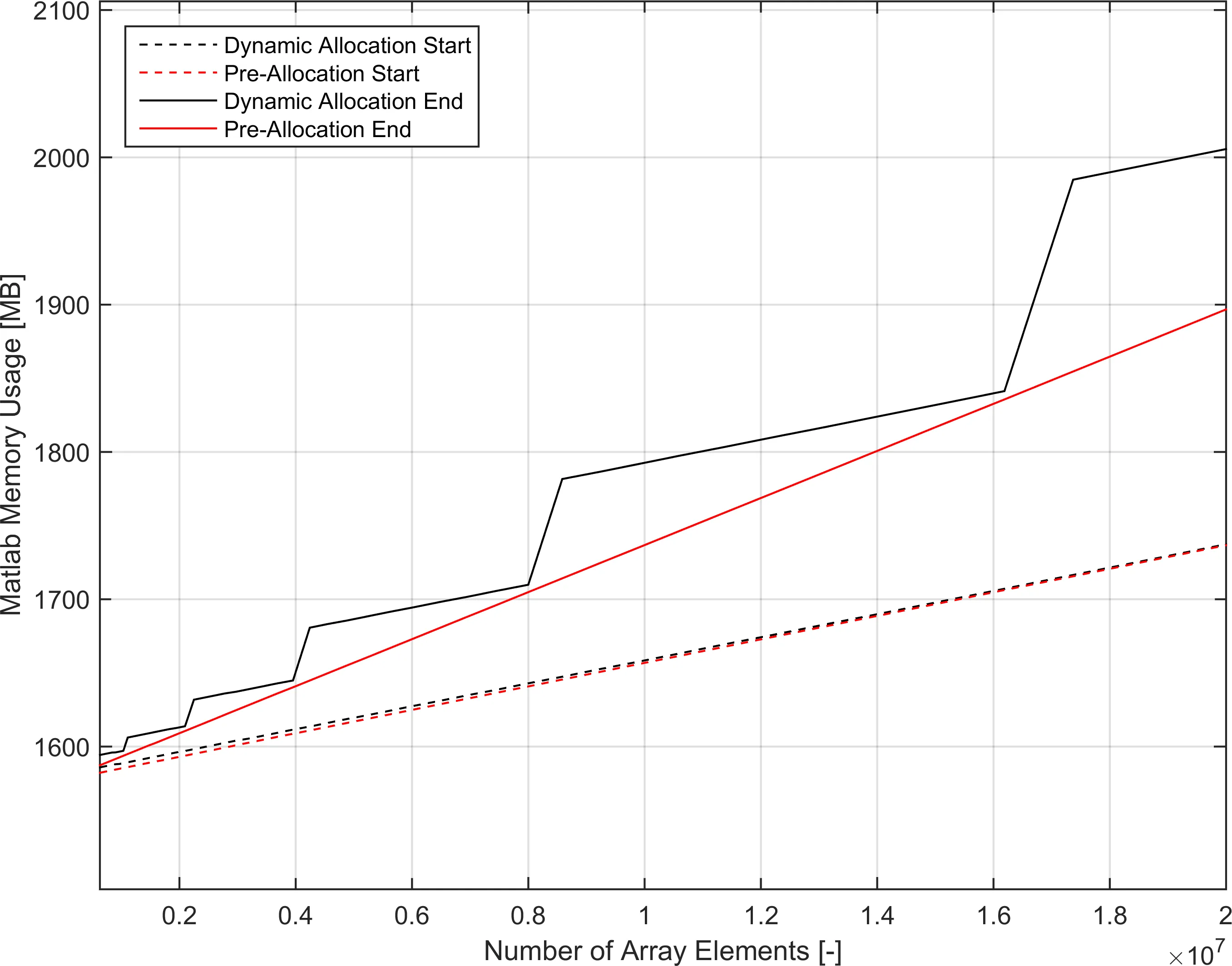
我发现这些结果很有趣,但除了上面的想法之外,我不能得出更多的结论。
然而,无论如何,在任何数字密集型应用程序中,显式预分配总是更好的,无论是运行时间还是代码维护方面。
当然,欢迎对结果和测试函数提出任何评论(可能讨论这个测试方法有什么问题)。这就是我(我们)学习的方式。
function [] = test()
funs = {@forDynamic,@forAllocate,@whileDynamic,@whileAllocate};
Nfun = numel(funs) ;
Nalloc = 2E7 ;
Nsamp = 50 ;
x = linspace(0,1,Nalloc) ;
nIndex = round(logspace(1,log10(Nalloc),Nsamp)) ;
times = repmat({zeros(1,Nsamp)},1,Nfun) ;
for k = 1:numel(funs)
f = funs{k};
for m = 1:Nsamp
tic;
f(x(1:nIndex(m)));
times{k}(m) = toc;
fprintf(['Iteration ',num2str(m,'%02G'),' of function ',num2str(k),' done.\n']);
end
end
figure(1);
args(2:2:2*Nfun) = times;
args(1:2:2*Nfun) = repmat({nIndex},1,Nfun);
loglog(args{:});
legend('Dynamic Allocation (for)','Pre-Allocation (for)','Dyanmic Allocation (while)','Pre-Allocation (while)','Location','Northwest');
grid('on');
axis([nIndex(1),nIndex(end),0.95*min([times{:}]),1.05*max([times{:}])]);
xlabel('Number of Array Elements [-]');
ylabel('Elasped Time [s]');
Nsamp = 50 ;
nIndex = round(10.^linspace(log10(Nalloc)-1.5,log10(Nalloc),Nsamp)) ;
mstart = repmat({zeros(1,Nsamp)},1,Nfun/2) ;
mend = repmat({zeros(1,Nsamp)},1,Nfun/2) ;
for k = 1:numel(funs)/2
f = funs{k};
for m = 1:Nsamp
[~,mstart{k}(m),mend{k}(m)] = f(x(1:nIndex(m)));
fprintf(['Iteration ',num2str(m,'%02G'),' of function ',num2str(k),' done.\n']);
end
end
figure(2);
mem = [mstart,mend];
args(2:2:2*Nfun) = mem ;
args(1:2:2*Nfun) = repmat({nIndex},1,Nfun);
h = plot(args{:});
set(h([1,2]),'LineStyle','--');
set(h([1,3]),'Color','k');
set(h([2,4]),'Color','r');
legend('Dynamic Allocation Start','Pre-Allocation Start','Dynamic Allocation End','Pre-Allocation End','Location','Northwest');
grid('on');
axis([nIndex(1),nIndex(end),0.95*min([mem{:}]),1.05*max([mem{:}])]);
xlabel('Number of Array Elements [-]');
ylabel('Matlab Memory Usage [MB]');
end
function y = burden(x)
y = besselj(0,x);
end
function mem = getMemory()
mem = memory();
mem = mem.MemUsedMATLAB/1E6;
end
function [y,mstart,mend] = forDynamic(x)
mstart = getMemory();
n = numel(x) ;
for k = 1:n
y(k) = burden(x(k));
end
mend = getMemory();
end
function [y,mstart,mend] = forAllocate(x)
mstart = getMemory();
n = numel(x) ;
y(1,n) = 0 ;
for k = 1:numel(x)
y(k) = burden(x(k));
end
mend = getMemory();
end
function [y,mstart,mend] = whileDynamic(x)
mstart = getMemory();
n = numel(x) ;
k = 1 ;
while k <= n
y(k) = burden(x(k)) ;
k = k + 1 ;
end
mend = getMemory();
end
function [y,mstart,mend] = whileAllocate(x)
mstart = getMemory();
n = numel(x) ;
k = 1 ;
y(1,n) = 0 ;
while k <= n
y(k) = burden(x(k)) ;
k = k + 1 ;
end
mend = getMemory();
end