测试
使用MatLab 2013b和Intel Xeon 3.6GHz + 16GB RAM,我运行下面的代码进行性能分析。我区分了3种方法,并仅考虑1D数组,即向量。方法1和2已经使用列向量和行向量进行测试,即(n,1)和(1,n)。
方法1(M1R,M1C)
a = zeros(1,n);
Method 2 M2R, M2C
a = NaN(1,n);
方法三(M3)
a(n) = 0;
结果
时间结果和元素数量已经在timing1D图中以双对数刻度绘制出来。
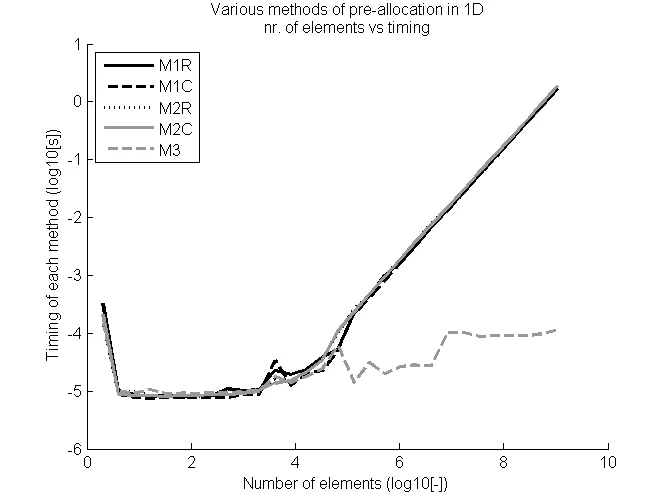
如图所示,第三种方法的分配几乎与向量大小无关,而其他方法逐步增加,表明向量的隐式定义。
讨论
MatLab使用JIT (Just in time)进行大量代码优化,即运行时代码优化。因此,一个有效的问题是是否由于编程(无论是否优化)还是优化导致代码运行更快的部分。通过使用feature('accel','off')可以关闭优化以测试这一点。再次运行代码的结果相当有趣:
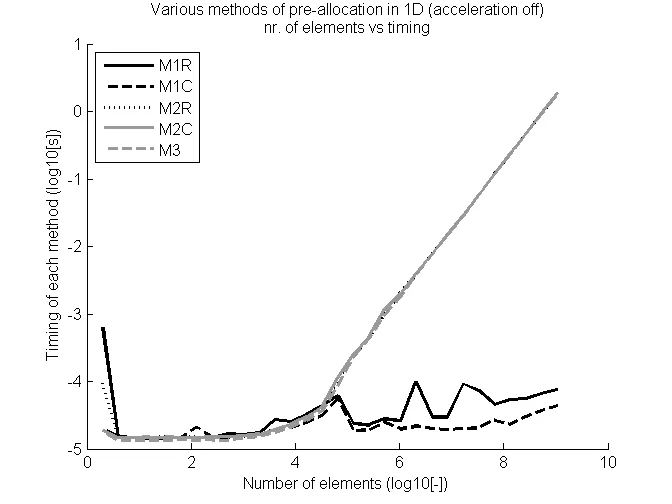
现在显示方法1是最佳的,不论是行向量还是列向量。并且方法3在第一次测试中的行为类似于其他方法。
结论
优化内存预分配是无用的,而且浪费时间,因为MatLab会为你进行优化。
请注意,应该预先分配内存,但是您执行的方式并不重要。预分配内存的性能很大程度上取决于MatLab的JIT编译器是否选择优化代码。这完全取决于.m文件中的所有其他内容,因为编译器一次考虑代码块然后尝试进行优化(甚至有一个内存,因此多次运行文件可能会导致执行时间更短)。此外,与之后执行的计算相比,预分配内存通常是一个非常短的过程。
我认为应该通过使用方法1或方法2来预先分配内存以保持可读性并使用MatLab帮助建议的函数,因为这些最有可能在未来得到改进。
使用的代码
clear all
clc
feature('accel','on')
number1D=30;
nn1D=2.^(1:number1D);
timings1D=zeros(5,number1D);
for ii=1:length(nn1D);
n=nn1D(ii);
tic
a = zeros(1,n);
a(randi(n,1))=1;
timings1D(1,ii)=toc;
fprintf('1D row vector method1 took: %f\n',timings1D(1,ii))
clear a
tic
b = zeros(n,1);
b(randi(n,1))=1;
timings1D(2,ii)=toc;
fprintf('1D column vector method1 took: %f\n',timings1D(2,ii))
clear b
tic
c = NaN(1,n);
c(randi(n,1))=1;
timings1D(3,ii)=toc;
fprintf('1D row vector method2 took: %f\n',timings1D(3,ii))
clear c
tic
d = NaN(n,1);
d(randi(n,1))=1;
timings1D(4,ii)=toc;
fprintf('1D row vector method2 took: %f\n',timings1D(4,ii))
clear d
tic
e(n) = 0;
e(randi(n,1))=1;
timings1D(5,ii)=toc;
fprintf('1D row vector method3 took: %f\n',timings1D(5,ii))
clear e
end
logtimings1D = log10(timings1D);
lognn1D=log10(nn1D);
figure(1)
clf()
hold on
plot(lognn1D,logtimings1D(1,:),'-k','LineWidth',2)
plot(lognn1D,logtimings1D(2,:),'--k','LineWidth',2)
plot(lognn1D,logtimings1D(3,:),'-.k','LineWidth',2)
plot(lognn1D,logtimings1D(4,:),'-','Color',[0.6 0.6 0.6],'LineWidth',2)
plot(lognn1D,logtimings1D(5,:),'--','Color',[0.6 0.6 0.6],'LineWidth',2)
xlabel('Number of elements (log10[-])')
ylabel('Timing of each method (log10[s])')
legend('M1R','M1C','M2R','M2C','M3','Location','NW')
title({'Various methods of pre-allocation in 1D','nr. of elements vs timing'})
hold off
注意
包含c(randi(n,1))=1的行只是将值1分配给预先分配的数组中的一个随机元素,以便使用该数组挑战JIT编译器。这些行不会对预分配测量产生重大影响,即它们无法测量并且不影响测试。
tic; a = NaN(1e4); a(1) = 1; toc确实比tic; a = zeros(1e4); a(1) = 1; toc慢。只是提醒一下,我只看到过使用zeros进行预分配,所以我非常确定除非你编写一个 mex 程序,否则没有办法在不初始化的情况下进行预分配,但也许其他人会知道。 - JustinBlaber