我想在我的React应用程序上使用Chrome审核工具,但它一直说我的robots.txt文件无效。问题是,文件似乎完全正常,只是它不读取robots.txt而是读取我的index.html文件,因此导致出现此错误:
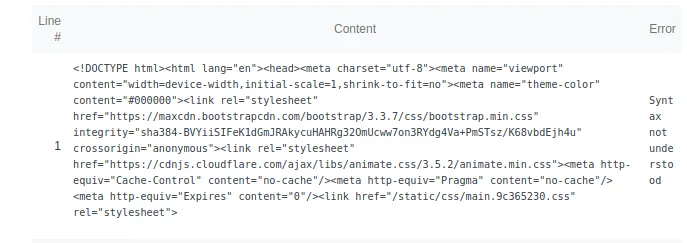
这两个文件都在我的 /public 文件夹中,为什么会读取 index 文件?
我想在我的React应用程序上使用Chrome审核工具,但它一直说我的robots.txt文件无效。问题是,文件似乎完全正常,只是它不读取robots.txt而是读取我的index.html文件,因此导致出现此错误:
这两个文件都在我的 /public 文件夹中,为什么会读取 index 文件?
app.get('/*', function (req, res) {
res.sendFile(path.join(__dirname, 'build', 'index.html'));
});
app.get('/robots.txt', function (req, res) {
res.sendFile(path.join(__dirname, 'build', 'robots.txt'));
});
app.get('/*', function (req, res) {
res.sendFile(path.join(__dirname, 'build', 'index.html'));
});