我开始学习CUDA,认为计算圆周率长数字会是一个不错的入门项目。
我已经实现了简单的蒙特卡罗方法,这很容易并行化。我让每个线程在单位正方形上随机生成点,计算有多少个点在单位圆内,并使用约简操作累积结果。
但这显然不是计算该常数的最快算法。以前,在单线程CPU上做这个练习时,我使用Machin-like formulae来进行远比较快的收敛计算。对于那些感兴趣的人,这涉及将pi表示为反正切的和,并使用泰勒级数来评估表达式。
其中一种公式如下:
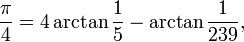
不幸的是,我发现将此技术并行化到数千个GPU线程不容易。问题在于大部分操作只是进行高精度数学运算,而不是在长数据向量上执行浮点运算。
因此,我想知道在GPU上计算任意长的圆周率数字的最有效方法是什么?