有许多论文描述了各种高级算法来进行集合划分。以下仅列出其中两篇:
老实说,我不知道哪个算法提供的解决方案更有效。也许这些高级算法都不需要用来解决SPOJ问题。Korf的论文仍然非常有用。其中描述的算法非常简单(易于理解和实现)。此外,他还概述了几种更简单的算法(在第2节中)。因此,如果您想了解Horowitz-Sahni或Schroeppel-Shamir方法的详细信息(如下所述),可以在Korf的论文中找到它们。此外(在第8节中),他写道随机方法不能保证足够好的解决方案。因此,使用类似爬山,模拟退火或禁忌搜索等方法可能不会带来显着的改进。
我尝试了几种简单算法及其组合来解决大小为10000,最大值为10
14,时间限制为4秒的分区问题。它们在随机均匀分布的数字上进行了测试。对于我尝试的每个问题实例,都找到了最优解。对于一些问题实例,算法可以保证最优性,而对于其他问题实例,最优性不能百分之百保证,但获得次优解的概率非常小。
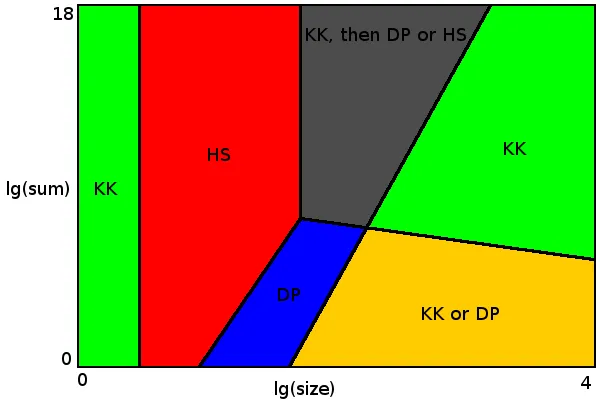
对于大小不超过4的情况(左侧的绿色区域),Karmarkar-Karp算法始终给出最优结果。
对于大小不超过54的情况,暴力算法足够快(红色区域)。可以选择Horowitz-Sahni或Schroeppel-Shamir算法。我使用了Horowitz-Sahni算法,因为在给定的限制条件下,它似乎更有效。Schroeppel-Shamir使用的内存要少得多(一切都适合L2高速缓存),因此当其他CPU核心执行一些内存密集型任务或使用多个线程进行集合分区时,它可能更可取。或者解决时间限制不那么严格的更大问题(在这种情况下,Horowitz-Sahni会耗尽内存)。
当大小乘以所有值的总和小于5*109(蓝色区域)时,动态规划方法是适用的。图表上暴力算法和动态规划区域的边界显示每个算法的性能更好的位置。
右边的绿色区域是Karmarkar-Karp算法几乎100%概率给出最优结果的地方。这里有很多完美的分区选项(具有Δ0或1),Karmarkar-Karp算法几乎肯定会找到其中之一。可能会发明数据集,其中Karmarkar-Karp始终给出次优解。例如{17 13 10 10 10 ...}。如果将其乘以某个大数,KK和DP都无法找到最优解。幸运的是,在实践中很少出现这种数据集。但问题设置者可以添加这样的数据集来使比赛更加困难。在这种情况下,您可以选择一些高级算法以获得更好的结果(但仅适用于图表上的灰色和右侧绿色区域)。
我尝试了两种实现Karmarkar-Karp算法优先队列的方法:使用最大堆和使用排序数组。排序数组选项似乎稍微快一些,具有线性搜索和二进制搜索显着更快。
黄色区域是您可以在DP中选择保证最优结果或者在Karmarkar-Karp中选择具有高概率的最优结果的地方。
最后,灰色区域,其中简单算法都无法给出最优结果。在这里,我们可以使用Karmarkar-Karp对数据进行预处理,直到它适用于Horowitz-Sahni或动态规划的其中之一。在这个地方也有许多完美的分区选项,但比绿色区域少,因此仅使用Karmarkar-Karp有时会错过正确的分区。更新:正如@mhum所指出的那样,不需要实现动态规划算法就可以使事情正常运行。Horowitz-Sahni与Karmarkar-Karp预处理就足够了。但是,对于Horowitz-Sahni算法在所述时间限制内处理大小达到54以(几乎)保证最优分区至关重要。因此,C++或其他具有良好优化编译器和快速计算机的语言更可取。
以下是我如何将Karmarkar-Karp与其他算法结合使用的方法:
template<bool Preprocess = false>
i64 kk(const vector<i64>& values, i64 sum, Log& log)
{
log.name("Karmarkar-Karp");
vector<i64> pq(values.size() * 2);
copy(begin(values), end(values), begin(pq) + values.size());
sort(begin(pq) + values.size(), end(pq));
auto first = end(pq);
auto last = begin(pq) + values.size();
while (first - last > 1)
{
if (Preprocess && first - last <= kHSLimit)
{
hs(last, first, sum, log);
return 0;
}
if (Preprocess && static_cast<double>(first - last) * sum <= kDPLimit)
{
dp(last, first, sum, log);
return 0;
}
const auto diff = *(first - 1) - *(first - 2);
sum -= *(first - 2) * 2;
first -= 2;
const auto place = lower_bound(last, first, diff);
--last;
copy(last + 1, place, last);
*(place - 1) = diff;
}
const auto result = (first - last)? *last: 0;
log(result);
return result;
}
完整的C++11实现链接。该程序仅确定分区和之间的差异,不会报告分区本身。 警告:如果您要在剩余内存少于1GB的计算机上运行它,请减少kHSLimit常量。