编辑:将速度提高到220微秒 - 请查看结尾处的编辑-直接版本
可以通过 自相关函数 或卷积等方式轻松计算所需的计算。维纳 - 金钦定理允许使用两个快速傅里叶变换(FFT)计算自相关,时间复杂度为O(n log n)。
我使用Scipy包中的加速卷积函数fftconvolve。一个好处是可以很容易地在这里解释它的工作原理。一切都是向量化的,在Python解释器级别没有循环。
from scipy.signal import fftconvolve
def difference_by_convol(x, W, tau_max):
x = np.array(x, np.float64)
w = x.size
x_cumsum = np.concatenate((np.array([0.]), (x * x).cumsum()))
conv = fftconvolve(x, x[::-1])
df = x_cumsum[w:0:-1] + x_cumsum[w] - x_cumsum[:w] - 2 * conv[w - 1:]
return df[:tau_max + 1]
- 与Elliot的答案中的
differenceFunction_1loop函数相比:使用FFT更快:430微秒相对于原来的1170微秒。在tau_max >= 40时开始变得更快。数值精度很高,最高相对误差小于1E-14相对于精确整数结果。(因此可以轻松地舍入到精确的长整数解决方案。)
- 参数
tau_max对算法不重要。它只是最终限制输出。在Python中,将索引从0开始添加一个零元素到输出。
- 参数
W在Python中并不重要。最好检查大小。
- 数据最初转换为np.float64以防止重复转换。这样可以快一半的速度。任何小于np.int64的类型都是不可接受的,因为会溢出。
- 所需的差异函数是双能量减去自相关函数。这可以通过卷积来评估:
correlate(x, x) = convolve(x, reversed(x)。
- “截至Scipy v0.19,正常的
convolve根据哪种方法更快的估计选择该方法或直接方法。”该启发式方法对于这种情况不足够,因为卷积评估的tau远比tau_max多,必须被更快的FFT超过直接方法。
- 可以通过将答案在matlab中使用FFT计算自相关性重写为Python(在末尾以下)来使用Numpy ftp模块进行计算。我认为上面的解决方案可能更容易理解。
证明:(针对Pythonista :-)
原始的naive实现可以写成:
df = [sum((x[j] - x[j + t]) ** 2 for j in range(w - t)) for t in range(tau_max + 1)]
当 tau_max < w 时。
根据规则推导得到 (a - b)**2 == a**2 + b**2 - 2 * a * b
df = [ sum(x[j] ** 2 for j in range(w - t))
+ sum(x[j] ** 2 for j in range(t, w))
- 2 * sum(x[j] * x[j + t] for j in range(w - t))
for t in range(tau_max + 1)]
通过使用 x_cumsum = [sum(x[j] ** 2 for j in range(i)) for i in range(w + 1)] 可以轻松在线性时间内计算的方法,将前两个元素替换掉。将 sum(x[j] * x[j + t] for j in range(w - t)) 替换为卷积 conv = convolvefft(x, reversed(x), mode='full'),其输出大小为 len(x) + len(x) - 1。
df = [x_cumsum[w - t] + x_cumsum[w] - x_cumsum[t]
- 2 * convolve(x, x[::-1])[w - 1 + t]
for t in range(tau_max + 1)]
通过向量表达式进行优化:
df = x_cumsum[w:0:-1] + x_cumsum[w] - x_cumsum[:w] - 2 * conv[w - 1:]
每个步骤都可以通过测试数据进行数值测试和比较。
编辑:直接使用Numpy FFT实现解决方案。
def difference_fft(x, W, tau_max):
x = np.array(x, np.float64)
w = x.size
tau_max = min(tau_max, w)
x_cumsum = np.concatenate((np.array([0.]), (x * x).cumsum()))
size = w + tau_max
p2 = (size // 32).bit_length()
nice_numbers = (16, 18, 20, 24, 25, 27, 30, 32)
size_pad = min(x * 2 ** p2 for x in nice_numbers if x * 2 ** p2 >= size)
fc = np.fft.rfft(x, size_pad)
conv = np.fft.irfft(fc * fc.conjugate())[:tau_max]
return x_cumsum[w:w - tau_max:-1] + x_cumsum[w] - x_cumsum[:tau_max] - 2 * conv
这个解决方案比我之前的解决方案更快两倍以上,因为卷积长度被限制在W + tau_max后最近的“好”数字上,并且具有小的质因数,而不是评估完整的2*W。与使用`fftconvolve(x, reversed(x))`时不必两次转换相同的数据。
In [211]: %timeit differenceFunction_1loop(x, W, tau_max)
1.1 ms ± 4.51 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [212]: %timeit difference_by_convol(x, W, tau_max)
431 µs ± 5.69 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [213]: %timeit difference_fft(x, W, tau_max)
218 µs ± 685 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
最新的解决方案在 tau_max >= 20 的情况下比Eliot的difference_by_convol更快。由于开销成本的相似比率,该比率不会很大程度上依赖数据大小。
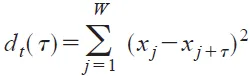
numba。你是否接受使用其他库? - Bharath M Shettyx有2048个元素,但你访问了第x[2047+105]个元素 - 你打算如何处理? - Martin Bonner supports Monica