这是我正在使用的数据样本:
SCENARIO DATE POD AREA IDOC STATUS TYPE
AAA 02.06.2015 JKJKJKJKJKK 4210 713375 51 1
AAA 02.06.2015 JWERWERE 4210 713375 51 1
AAA 02.06.2015 JAFDFDFDFD 4210 713375 51 9
BBB 02.06.2015 AAAAAAAA 5400 713504 51 43
CCC 05.06.2015 BBBBBBBBBB 4100 756443 51 187
AAA 05.06.2015 EEEEEEEE 4100 756457 53 228
我已经使用pandas编写了以下代码进行分组:
```python ```
import pandas as pd
import numpy as np
xl = pd.ExcelFile("MRD.xlsx")
df = xl.parse("Sheet3")
#print (df.column.values)
# The following gave ValueError: Cannot label index with a null key
# dfi = df.pivot('SCENARIO)
# Here i do not actually need it to count every column, just a specific one
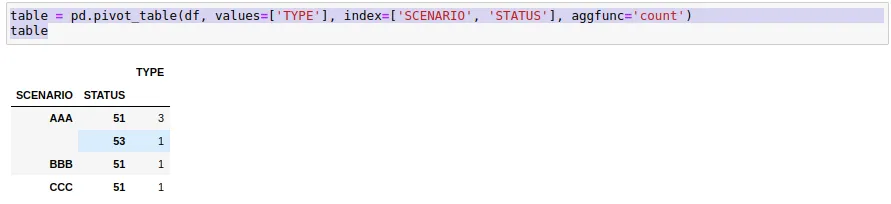
table = df.groupby(["SCENARIO", "STATUS", "TYPE"]).agg(['count'])
writer = pd.ExcelWriter('pandas.out.xlsx', engine='xlsxwriter')
table.to_excel(writer, sheet_name='Sheet1')
writer.save()
table2 = pd.DataFrame(df.groupby(["SCENARIO", "STATUS", "TYPE"])['TYPE'].count())
print (table2)
writer2 = pd.ExcelWriter('pandas2.out.xlsx', engine='xlsxwriter')
table2.to_excel(writer2, sheet_name='Sheet1')
writer2.save()
这将产生一个结果:
SCENARIO STATUS TYPE TYPE
AAA 51 1 2
9 1
53 228 1
BBB 51 43 1
CCC 51 187 1
Name: TYPE, dtype: int64
如何在每个分组中添加小计?理想情况下,我希望实现类似于以下内容的效果:
SCENARIO STATUS TYPE TYPE
AAA 51 1 2
9 1
Total 3
53 228 1
Total 1
BBB 51 43 1
Total 1
CCC 51 187 1
Total 1
Name: TYPE, dtype: int64
这是可能的吗?
Total在TYPE层级中,是否有问题? - jezrael