我有一个带有以下列的数据框:
我想创建一个名为 Z 的新列,它将每一行分组成一个 JSON 记录列表,并将该列重命名为它们的键。构建完 JSON 列后,我想删除所有列,只保留 Z 和 ID 列。
期望的输出如下:
问题在于我无法重命名列,使得只保留字母而去除数字,就像上面的例子一样。运行上述代码还没有把每组3个元素分开成一个对象,而是创建了两个列表对象。如果可能的话,我希望用Pandas实现这个功能。如有任何指导,将不胜感激。
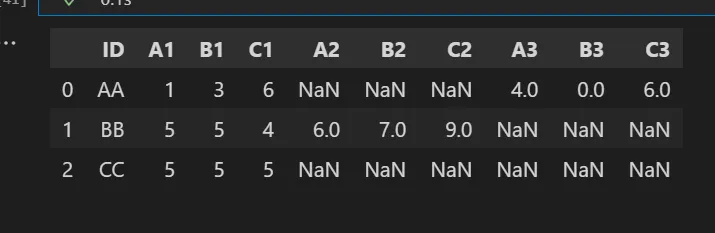
ID A1 B1 C1 A2 B2 C2 A3 B3 C3
AA 1 3 6 4 0 6
BB 5 5 4 6 7 9
CC 5 5 5
我想创建一个名为 Z 的新列,它将每一行分组成一个 JSON 记录列表,并将该列重命名为它们的键。构建完 JSON 列后,我想删除所有列,只保留 Z 和 ID 列。
期望的输出如下:
ID Z
AA [{"A":1, "B":3,"C":6},{"A":4, "B":0,"C":6}]
BB [{"A":5, "B":5,"C":4},{"A":6, "B":7,"C":9}]
CC [{"A":5, "B":5,"C":5}]
这是我的目前尝试:
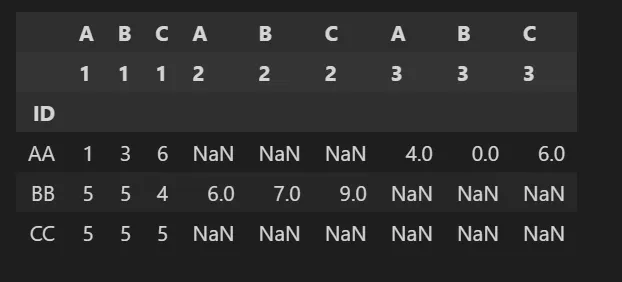
df2 = df.groupby(['ID']).apply(lambda x: x[['A1', 'B1', 'C1',
'A2', 'B2', 'C2', 'A3', 'B3', 'C3']].to_dict('records')).to_frame('Z').reset_index()
问题在于我无法重命名列,使得只保留字母而去除数字,就像上面的例子一样。运行上述代码还没有把每组3个元素分开成一个对象,而是创建了两个列表对象。如果可能的话,我希望用Pandas实现这个功能。如有任何指导,将不胜感激。

AA 1 3 6 4 0 6 BB 5 5 4 6 7 9
CC 5 5 5 `最后有一个随机的反引号,请让我知道您对输出问题有什么建议。 - ApacheOne