我认为你需要在groupby的末尾添加列i,然后用于sum函数:
df2 = df2.groupby(['a', 'b'])['i'].sum().reset_index()
print (df2)
a b i
0 1.0 3.0 29.0
1 1.0 4.0 4.0
或者添加参数 as_index=False 以返回 df:
df2 = df2.groupby(['a', 'b'], as_index=False)['i'].sum()
print (df2)
a b i
0 1.0 3.0 29.0
1 1.0 4.0 4.0
如果需要的话,另一个解决方案是使用 Series:
df2 = df2.i.groupby([df2.a,df2.b]).sum().reset_index()
print (df2)
a b i
0 1.0 3.0 29.0
1 1.0 4.0 4.0
编辑:
如果需要按df中的位置区分组,请使用Series g通过aggregate的groupby功能:
ab = df2[['a','b']]
#compare shifted values
print (ab.ne(ab.shift()))
a b
0 True True
1 False False
2 False False
3 False False
4 False False
5 False False
6 False True
7 False False
8 False True
9 False False
10 False False
#check at least one True
print (ab.ne(ab.shift()).any(1))
0 True
1 False
2 False
3 False
4 False
5 False
6 True
7 False
8 True
9 False
10 False
dtype: bool
g = ab.ne(ab.shift()).any(1).cumsum()
print (g)
0 1
1 1
2 1
3 1
4 1
5 1
6 2
7 2
8 3
9 3
10 3
dtype: int32
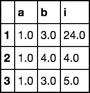
print (df2.groupby(g).agg(dict(a='first', b='first', i='sum')))
a b i
1 1.0 3.0 24.0
2 1.0 4.0 4.0
3 1.0 3.0 5.0