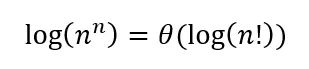通过插入函数“insert(A,n)”在堆中插入新元素需要O(log n)的时间(其中n是数组'A'中元素的数量)。插入函数如下所示:
void insert(int A[], int n)
{
int temp,i=n;
cout<<"Enter the element you want to insert";
cin>>A[n];
temp=A[n];
while(i>0 && temp>A[(i-1)/2])
{
A[i]=A[(i-1)/2];
i=(i-1)/2;
}
A[i]=temp;
}
插入函数的时间复杂度为O(log n)。
将数组转换为堆数组的函数如下:
void create_heap()
{
int A[50]={10,20,30,25,5,6,7};
//I have not taken input in array A from user for simplicity.
int i;
for(i=1;i<7;i++)
{
insert(A,i);
}
}
给出的这个函数的时间复杂度是O(nlogn)。
-> 但是,在每次调用中,插入函数最多要比较'i'个元素。也就是说,每次循环单次时间复杂度为O(log i)。
-> 所以首先是log1,然后是log2,然后是log3等等,直到log6。
-> 对于一个数组的n个元素,总时间复杂度将是 log2 + log3 + log4 +....logn
-> 这将是log(2x3x4x...xn) = log(n!)
那么为什么时间复杂度不是O(log(n!))而是O(nlogn)?